
感谢晓哥原创,此处记录,并做一个 bug 的分析记录。
什么是 perf?
perf 工具可以用于分析内核和用户态进程的性能,它提供了一种强大的性能分析工具,可以帮助开发人员诊断和优化系统性能问题。
在 Linux 系统中,perf 工具使用了 Linux 内核中的性能计数器和跟踪事件机制,可以对内核和用户态进程进行性能分析。具体来说,perf 工具可以用于以下方面的性能分析:
1.内核性能分析:perf 工具可以使用内核性能计数器和跟踪事件机制,对内核进行性能分析。例如,可以使用 perf 工具分析内核函数的执行时间、中断处理程序的响应时间、系统调用的执行时间等。此外,perf 工具还可以对内核事件进行跟踪和分析,如 CPU 使用率、内存使用情况、磁盘 I/O、网络流量等。
2.用户态进程性能分析:perf 工具也可以用于对用户态进程进行性能分析。例如,可以使用 perf 工具分析进程的 CPU 使用率、内存使用情况、磁盘 I/O、网络流量等。此外,perf 工具还可以对进程的函数调用进行跟踪和分析,以便查找性能瓶颈和优化代码。
总之,perf 工具可以用于分析内核和用户态进程的性能,它提供了一种强大的性能分析工具,可以帮助开发人员诊断和优化系统性能问题。
系统级性能优化通常包括两个阶段:性能剖析( performance profiling )和代码优化。性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。本篇主要讲性能分析中常用的工具 ——perf 。
Perf 全名是 Performance Event ,是在 Linux 2.6.31 以后内建的系统效能分析工具,依靠 perf ,应用程式可以利用 PMU (Performance Monitoring Unit), tracepoint 和核心内部的特殊计数器 (counter) 来进行统计,另外还能同时分析运行中的核心程式码,从而更全面了解应用程式中的效能瓶颈。
Perf 可以解决高级性能和故障排除,它可以分析 :
- 为什么内核消耗 CPU 高 , 代码的位置在哪里?
- 什么代码引起了 CPU 2 级 cache 未命中?
- CPU 是否消耗在内存 I/O 上?
- 哪些代码分配内存,分配了多少?
- 什么触发了 TCP 重传?
- 某个内核函数是否正在被调用,调用频率多少?
- 线程释放 CPU 的原因?
perf 的原理
性能计数器是现代 CPU 中一些特殊的硬件寄存器。这些寄存器对特定的硬件事件进行计数:比如指令的执行, cache miss 或者是分支预测错误等,同时不会对内核或应用的性能产生影响。这些寄存器中的内容可以被定期收集,同时这些寄存器也可以在特定的事件数量超过一定数值时触发中断。而在这些中断中,特定的事件数量被记录,并在应用层需要时返回这些数据。这样,使得开发者能够收集代码执行过程中某些事件比如 cache miss ,内存引用以及 CPU clock 或 cycle 等的相关信息,并使得开发者能够根据它们来判断代码的运行情况及其原因。
详⻅ CPU PMU 文档
perf event
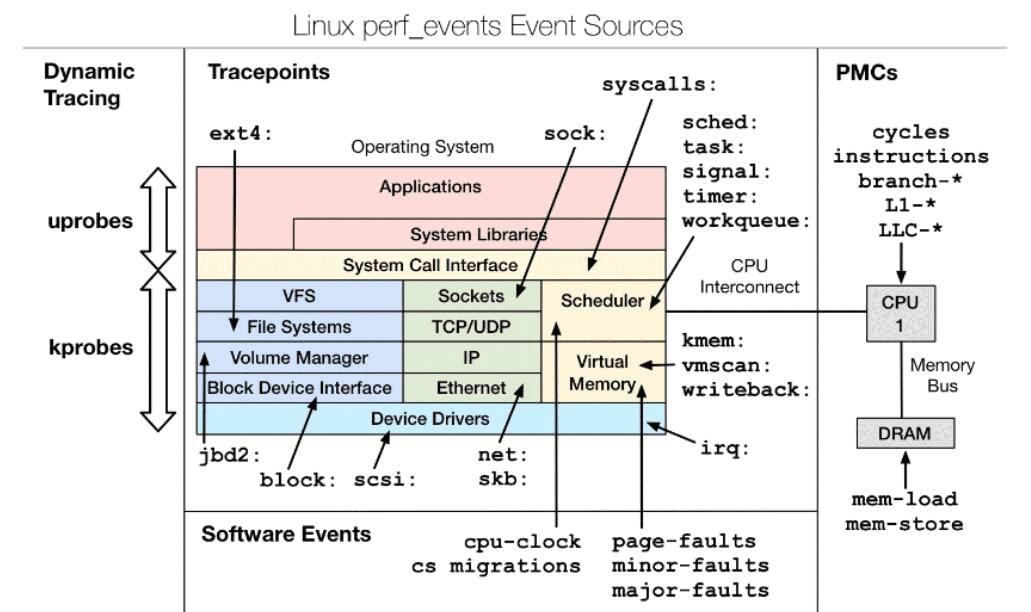
利用 CPU performance counters( 性能计数器 ) , tracepoints, kprobes 和 uprobes 来进行应用程序的性能分析。 perf 使用这些 linux 内核提供的 tracing 特性进行事件的采集和分析, perf 使用的 event 主要有以下几种:
- Hardware Events: CPU 中的寄存器含有 performance counters( 性能计数器 ) ,用来统计
Hardware event ,例如 cpu-cycles 、 instructions executed 、 cache-misses 、 branch mispredicted 等。这些 event 构成了应用程序 profiling 的基础。
- Software Events: 基于内核计数器的低优先级 events , 例如 , CPU migrations( 处理器迁移次数 ),
minor faults(soft page faults), major faults(hard page faults).
- Tracepoints:是散落在内核源代码中的一些 hook ,用来调用 probe 函数,开启后,它们便可以在
特定的代码被运行到时被触发,这一特性可以被各种 trace/debug 工具所使用。 Perf 就是该特性的用戶之一。假如您想知道在应用程序运行期间,内核内存管理模块的行为,便可以利用潜伏在 slab 分配器中的 tracepoint 。当内核运行到这些 tracepoint 时,便会通知 perf 。
- Dynamic Tracing : probe 函数 ( 探针 or 探测函数 ) , kprobe(kernel probe) 内核态探针,用来创建
和管理内核代码中的探测点。 Uprobes , user-probe ,用戶态探针,用来对用戶态应用程序进行探测点的创建和管理。
perf 的使用
- 安装
sudo apt install linux-perf
- 查看版本
perf –version
- perf 是一个包含 23 个工具
| 序号 | 命令 | 作用 |
|---|---|---|
| 1 | annotate | 解析 perf record 生成的 perf.data 文件,显示被注释的代码。 |
| 2 | archive | 根据数据文件记录的 build-id ,将所有被采样到的 elf 文件打包。利用此压缩包,可以再任何机器上分析数据文件中记录的采样数据。 |
| 3 | bench | perf 中内置的 benchmark,目前包括两套针对调度器和内存管理子系统的 benchmark。 |
| 4 | build-id-cache | 管理 perf 的 buildid 缓存,每个 elf 文件都有一个独一无二的 buildid 。 buildid 被 perf 用来关联性能数据与 elf 文件。 |
| 5 | build-id-list | 列出数据文件中记录的所有 buildid 。 |
| 6 | diff | 对比两个数据文件的差异。能够给出每个符号(函数)在热点分析上的具体差异。 |
| 7 | evlist | 列出数据文件 perf.data 中所有性能事件。 |
| 8 | inject | 该工具读取 perf record 工具记录的事件流,并将其定向到标准输出。在被分析代码中的任何一点,都可以向事件流中注入其它事件。 |
| 9 | kmem | 针对内核内存( slab )子系统进行追踪测量的工具 |
| 10 | kvm | 用来追踪测试运行在 KVM 虚拟机上的 Guest OS 。 |
| 11 | list | 列出当前系统支持的所有性能事件。包括硬件性能事件、软件性能事件以及检查点。 |
| 12 | lock | 分析内核中的锁信息,包括锁的争用情况,等待延迟等。 |
| 13 | mem | 内存存取情况 |
| 14 | record | 收集采样信息,并将其记录在数据文件中。随后可通过其它工具对数据文件进行分析。 |
| 15 | report | 读取 perf record 创建的数据文件,并给出热点分析结果。 |
| 16 | sched | 针对调度器子系统的分析工具。 |
| 17 | script | 执行 perl 或 python 写的功能扩展脚本、生成脚本框架、读取数据文件中的数据信息等。 |
| 18 | stat | 执行某个命令,收集特定进程的性能概况,包括 CPI 、 Cache 丢失率等。 |
| 19 | test | perf 对当前软硬件平台进行健全性测试,可用此工具测试当前的软硬件平台是否能支持 perf 的所有功能。 |
| 20 | timechart | 针对测试期间系统行为进行可视化的工具 |
| 21 | top | 类似于 linux 的 top 命令,对系统性能进行实时分析。 |
| 22 | trace | 关于 syscall 的工具。 |
| 23 | probe | 用于定义动态检查点。 |
- perf 的全局命令
perf list:查看当前系统支持的性能事件;
perf bench:对系统性能进行摸底;
perf test:对系统进行健全性测试;
perf stat:对全局性能进行统计;
- perf list
选项列出了所有的符号事件类型,包括硬件、软件和内核事件。
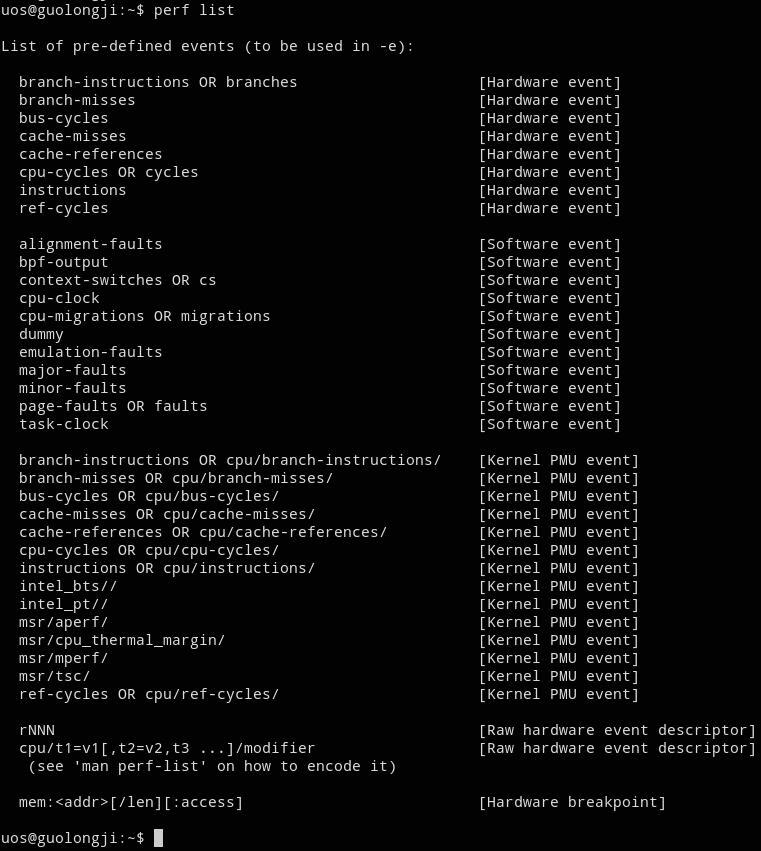
可以看到事件分为三类: Hardware event 硬件事件、 Software event 软件事件和 Hardware cache event 事件。
- hw/hardware 显示支持的硬件事件相关
uos@guolongji:~$ perf list hw
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]
- sw/software 显示支持的软件事件列表
uos@guolongji:~$ perf list sw
List of pre-defined events (to be used in -e):
alignment-faults [Software event]
bpf-output [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
- cache/hwcache 显示硬件 cache 相关事件列表
uos@guolongji:~$ perf list cache
List of pre-defined events (to be used in -e):
L1-dcache-load-misses [Hardware cache event]
L1-dcache-loads [Hardware cache event]
L1-dcache-prefetch-misses [Hardware cache event]
L1-dcache-prefetches [Hardware cache event]
perf stat
执行命令期间执行指定命令并计算发生的事件,并在三列中显示这些计数的统计信息:
给定事件的出现次数
所计算的事件的名称
当相关指标可用时,最右侧列中的 hash 符号 ( # ) 后会显示一个比率或百分比。例如,当以默认模式运行时, perf stat 计算周期和指令,因此在最右侧列中计算并显示每个周期的说明。您可以看到与分支缺少相关的类似行为,因为默认情况下这
两个事件都被计算为两个分支的百分比。
root@uos-PC:/home/uos# perf stat ls
0001-feat-add-loongarch64-gsgpu-support.diff deepin-sw64-0001.patch libdrm Pictures
0001-feat-add-loongarch64-gsgpu-support.patch deepin-sw64-porting-cmake.patch libglvnd series
0002-feat-build-libdrm-etnaviv1-package-on-loongarch64.patch Desktop mesa source
add-loongarch-support-cmake.patch Documents mesa23_backup src
changelog Downloads mesa-utils updir
cl.diff innogpu_2.2.b4.rev3-UOS_amd64.deb Music Videos
commit-msg innogpu-kernel-2.2.b4.rev3-UOS_amd64.deb patches
Performance counter stats for 'ls':
0.49 msec task-clock # 0.750 CPUs utilized
0 context-switches # 0.000 K/sec
0 cpu-migrations # 0.000 K/sec
103 page-faults # 0.000 K/sec
1,959,599 cycles
1,764,610 instructions # 0.90 insn per cycle
372,897 branches # 0.000 K/sec
14,576 branch-misses # 3.91% of all branches
0.000647272 seconds time elapsed
0.000686000 seconds user
0.000000000 seconds sys
perf top
实时查看当前系统进程函数占用率情况。
线程使用的 CPU 时间, perf top 显示每个特定功能使用的 CPU 时间。在默认状态下, perf top 告知用戶空间和内核空间的所有 CPU 中使用的功能。
perf top 可以用于观察系统和软件内性能开销最大的函数列表。通过观察不同事件的函数列表可以分析出不同函数的性能开销情况和特点,判断其优化方向。例如如果某个函数在 perf top -e instructions 中排名靠后,却在 perf top -e cache-misses 和 perf top -e cycles 中排名靠前,说明函数中存在大量 cache-miss 造成 CPU 资源占用较多,就可以考虑优化该函数中的内存访问次数和策略,来减少内存访问和 cache-miss 次数,从而降低 CPU 开销。
在较新的内核版本中, perf top 还可以深入到函数对应的汇编指令中,明确指出是哪些指令占用了计算资源,可以非常明确的指明软件性能热点。
执行 perf top 显示如下:
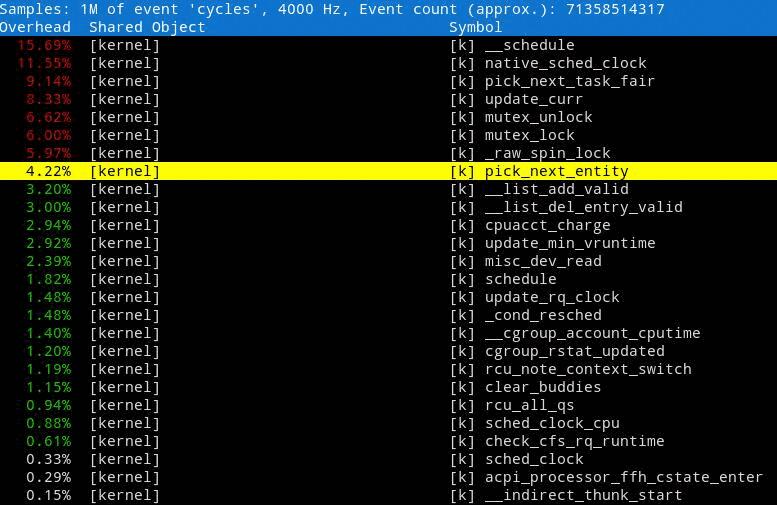
监控界面在几个列中显示数据:
- “Overhead” 列
显示给定功能正在使用的 CPU 百分比。
- " 共享对象 " 列
显示使用 函数的程序或库的名称。
- “Symbol” 列
显示函数名称或符号。内核空间中执行的功能由 [k] 标识,用戶空间执行的功能由 [.] 标识。
查看具体进程用: perf top -p 16279
perf probe
自定义动态事件
perf 特定功能分析
perf kmem 针对 slab 子系统性能分析
perf kvm 针对 kvm 虚拟化分析
perf lock 分析锁性能
perf mem 分析内存 slab 性能
perf sched 分析内核调度器性能
perf trace 记录系统调用轨迹
perf record
The perf tool can be used to collect profiles on per-thread, per-process and per-cpu basis.There are several commands associated with sampling: record , report , annotate . You must first collect the samples using perf record . This generates an output file called perf.data . That file can then be analyzed, possibly on another machine, using the perf report and perf annotate commands.
perf 工具可用于收集每个线程、每个进程和每个 CPU 上的基础轮廓。有几个与采样相关的命令:record、report、annotate。你必须首先使用 perf record 收集样本。这将生成一个名为性能数据 .然后可以使用 perf report 分析该文件,可能在另一台计算机上进行分析和性能注释命令。
perf record 参数说明:
- -a: 全局的 CPU 栈函数跟踪;
在被监控 CPU 上的所有线程中同时使用 perf record 在每个 CPU 模式中对用戶空间和内核空间的性能数据进行抽样和记录。默认情况下,按 CPU 模式监控所有在线 CPU 。
-o: 指定输出文件;
-F: 事件采样的频率 , 单位 HZ, 更高的频率会获得更细的统计,但会带来更多的开销;
-g: 进行堆栈追踪,生成调用关系图,等价于 –call-graph , 默认情况下, -g 等同于 –call-graph fp ,
即通过 frame pointer 来进行堆栈追踪。 如果 frame pointer 被优化掉的话,可以通过 dwarf, lbr 进行堆栈追踪;
- – sleep: 采样的时间
perf record -F 99 -p 2338 -g -- sleep 30
表示每秒 99 次, -p 2338 是进程号,即对哪个进程进行分析, -g 表示记录调用栈, sleep 30 则是持续 30 秒。
perf report
perf report -i perf.data
可视化工具
参考:https://blog.csdn.net/oujiangping/article/details/78454881
#include <iostream>
#include <thread>
#include <unistd.h>
void test() {
int i = 0;
while(i < 5000000000) i++;
}
int main() {
std::thread *th[12];
for(int i = 0; i < 12; i++) {
th[i] = new std::thread(test);
}
for(int i = 0; i < 12; i++) {
th[i]->join();
delete th[i];
}
return 0;
}
./thread
新的终端下运行:
sudo perf timechart record
几秒后 ctl+c 中断
sudo perf timechart
结果输出在 output.svg 当中。
linux 内核中的 perf event 子系统
PMU (Performance Monitoring Unit) 是一种硬件组件,通常集成在现代处理器中,用于监测和记录处理器的性能指标和事件。
PMU 可以提供大量的性能计数器,用于度量处理器的各种指标,如指令执行数、缓存命中率、分支预测错误次数等。通过配置和读取这些计数器,开发人员可以获取有关程序执行的详细性能数据,以便进行性能分析和优化。
PMU 还可以监测处理器的事件,如缓存失效、分支预测错误、TLB (Translation Lookaside Buffer) 错误等。这些事件可以帮助开发人员了解程序执行期间发生的异常情况,并进行故障诊断和性能调优。
PMU 的功能和特性因处理器而异,不同的处理器可能提供不同数量和类型的性能计数器,支持不同的事件监测。为了使用 PMU,开发人员通常需要使用特定的性能分析工具,如 perf、PAPI (Performance Application Programming Interface) 等,这些工具提供了对 PMU 的抽象接口和高级功能,使开发人员能够方便地进行性能分析和优化。
总结来说,PMU 是一种硬件组件,用于监测和记录处理器的性能指标和事件。它提供性能计数器和事件监测功能,可以帮助开发人员获取有关程序执行的详细性能数据,并进行性能分析和优化。
网上有很多 perf 架构的博客,等我有时间了有兴趣了再详细看代码,大多数时候会用就可以了:
https://blog.csdn.net/pwl999/article/details/81200439
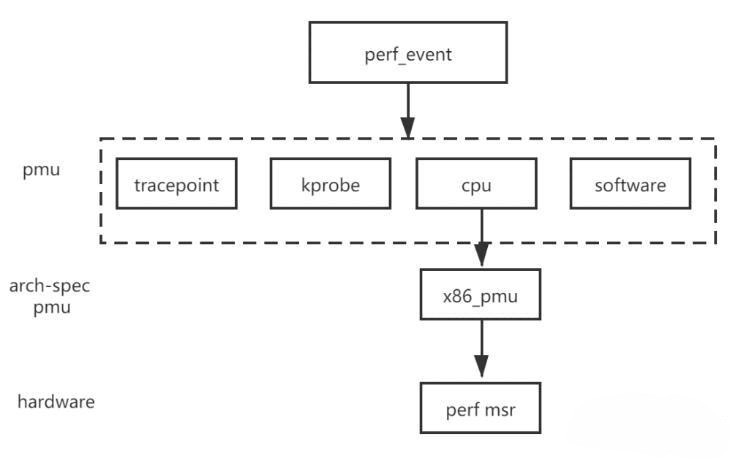
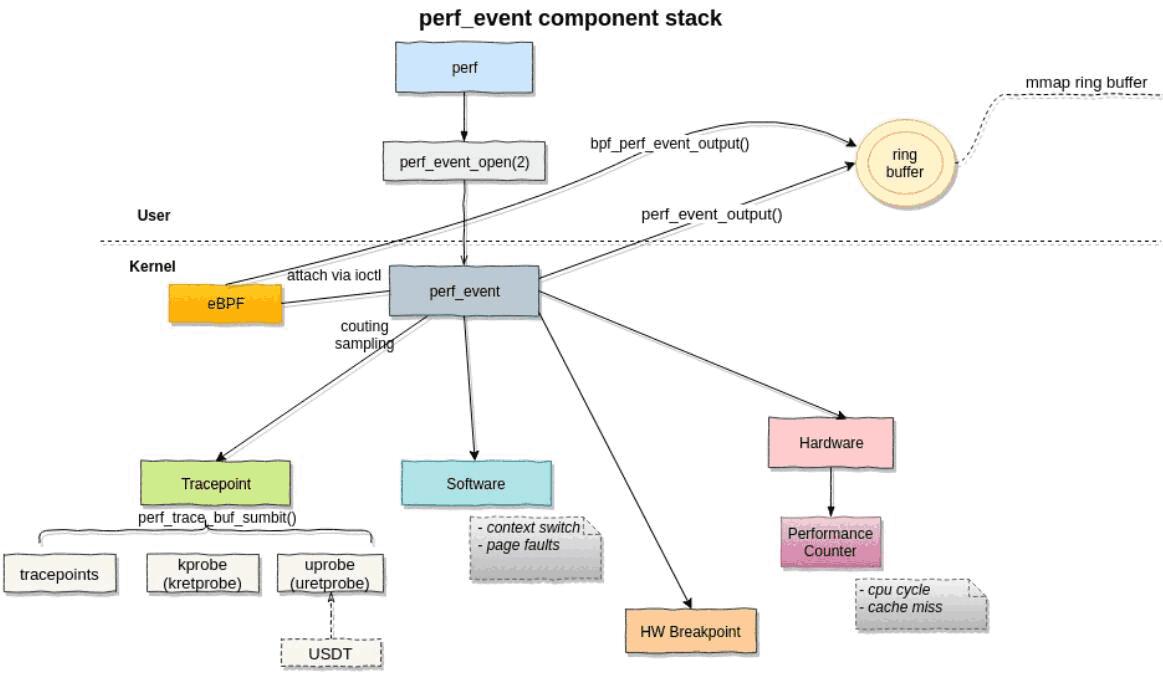
Figure 1: perf 子系统架构图
火焰图
火焰图( Flame Graph )是由 Linux 性能优化大师 Brendan Gregg 发明的,和所有其他的 profiling 方法不同的是,火焰图以一个全局的视野来看待时间分布,它从底部往顶部,列出所有可能导致性能瓶颈的调用栈。
火焰图是基于 perf 结果产生的 SVG 图片,用来展示 CPU 的调用栈。
命令行:sudo perf report -n –stdio
也能看到比较直观的内容。更直观的只能是火焰图。
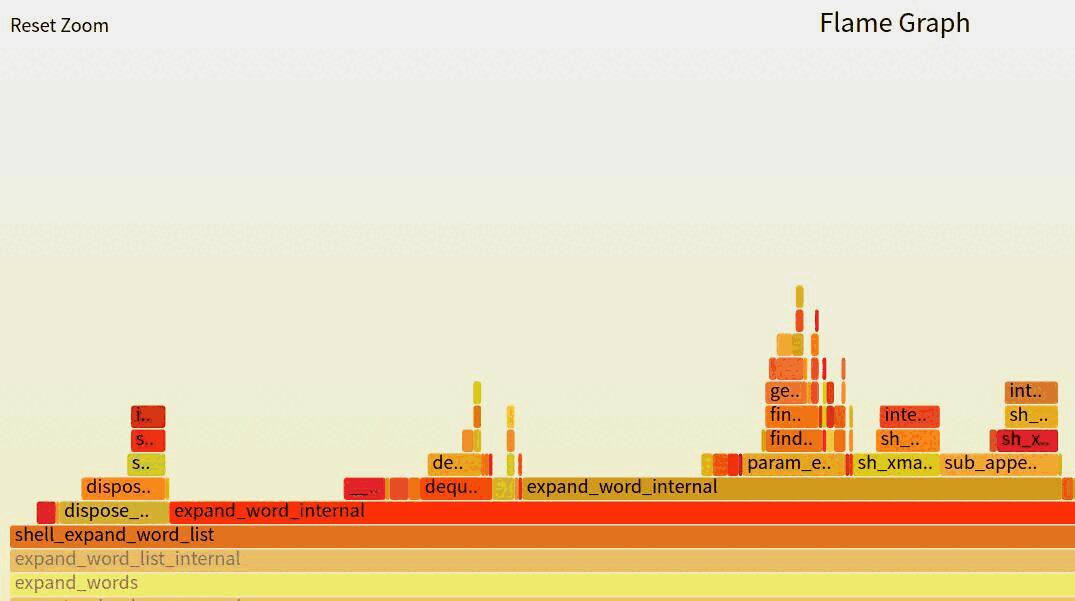
Figure 2: 火焰图示例
一列 box 代表一个 stack trace ,每个 box 代表一个 stack frame 。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间
⻓。注意, x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
- y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下
方都是它的父函数。
火焰的每一层都会标注函数名,鼠标悬浮时会显示完整的函数名、抽样抽中的次数、占据总抽样次数的百分比。火焰图就是看顶层的哪个函数占据的宽度最大。只要有 " 平顶 " ( plateaus ),就表示该函数可能存在性能问题。
常⻅的火焰图类型有 On-CPU , Off-CPU ,还有 Memory , Hot/Cold , Differential 等等。
比较长的延时我认为一定是能通过 perf 这个工具来分析的。那么怎么分析呢?
操作:
- 点击放大
在某一层点击,火焰图会水平放大,该层会占据所有宽度,显示详细信息。左上⻆会同时显示 “Reset Zoom” ,点击该链接,图片就会恢复原样。
- 搜索
按下 Ctrl + F 会显示一个搜索框,用戶可以输入关键词或正则表达式,所有符合条件的函数名会高亮显示。
使用过程
- 可视化生成器
git clone https://github.com/brendangregg/FlameGraph.git
- 采集数据
perf record -p pid -g – sleep 30
- 读取数据
perf report -n --stdio # 读取 perf.data 并显示百分比等
perf script --header # 显示 perf.data 的所有事件的数据头
- 生成火焰图
perf script -i perf.data &> perf.unfold
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
./FlameGraph/flamegraph.pl perf.folded > perf.svg
通过 chrome 或者看图软件打开 perf.svg 。
- 用脚本从写一下:
#!/bin/sh
DIR=/your-path/
sudo perf record -F 99 -p $1 -g -- sleep $2
sudo perf script -i perf.data > $DIR/cpu.perf
./FlameGraph/stackcollapse-perf.pl $DIR/cpu.perf > $DIR/cpu.folded
./FlameGraph/flamegraph.pl $DIR/cpu.folded > $DIR/cpu1.svg
linux 用户切换过程偶发的黑屏切换缓慢问题
这个问题是在 A 卡的 oland 系列的显卡上出现的一个小问题。因为涉及到 DE,lightdm,dbus,kernel,显卡驱动多方面的因素。所以分析起来没什么头绪。
一个想法是用 perf 记录所有的调用过程,这样是不是能找到最耗时的地方。
perf record -a -F 99 -o perf.data
使用 -a 参数会报 VDSO 还有其它很多的包没有 symbols。perf report -s 可以增加 symbol。直接用-a 参数是无法分析的。
切换这个过程涉及到哪些程序呢?
参考博客
https://queue.acm.org/detail.cfm?id=2927301
https://perf.wiki.kernel.org/index.php/Main_Page
https://perf.wiki.kernel.org/index.php/Tutorial
https://www.cnblogs.com/arnoldlu/p/6241297.html
http://walkerdu.com/2018/09/13/perf-event/
https://pingcap.com/zh/blog/flame-graph
https://www.brendangregg.com/perf.html
http://github.tiankonguse.com/blog/2016/03/29/perf-record.html
https://www.ruanyifeng.com/blog/2017/09/flame-graph.html
https://jasonblog.github.io/note/linux_tools/xi_tong_ji_xing_neng_fen_xi_gong_ju__perf.html
https://www.collabora.com/news-and-blog/blog/2017/03/21/performance-analysis-in-linux/
http://liujunming.top/2018/05/10/perf%E5%86%85%E6%A0%B8%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90/