
这两个是胡晓东大佬先分析,余晟锦大佬又分析了后面的问题。这个问题很典型,这是个典型的信号量 bug ,也是申威架构考虑不周全的地方。或者说是用户态的 xorg 对 sw 架构的考虑不周全。
学习一下别人的调试工具和分析思路。这个问题让我知道可以用 bpf 的 uprobe 来监视用户态库的调用者有哪些?这样可以大而全的排除问题。
前人分析
问题描述
跑 ltp 大概不到 1 分钟,桌面就会卡死,停掉 ltp 压测负载,仍然卡死,重启 kwin 进程,桌面可以恢复。
原因分析
根据问题现象,最初猜测可能有两个方向:
- vblank 事件处理流程除了问题 ;
- buffer 同步方面出了问题。
从 Xorg 这一段观察,桌面正常时,桌面上只要有刷新, kwin 就会发送 present pixmap 请求给 Xorg , Xorg 再将 pixmap 数据通过 pagflip 方式送显出去,出问题时, kwin 停止了向 Xorg 发送 preset pixmap 请求。
present pixmap 是 DRI3 的一个扩展功能,客户端渲染完一帧数据后,就向 Xorg 发送真的请求, Xorg 通过 pixmp 描述信息,找到对应的共享 bufer id (即 handle ), 然后将这个共享 buffer 数据在一个特定的 vblank 上送显出去。 DRI2 不走这个流程,于是我就修改了 xorg 配置,让其是用 DRI2 渲染,结果就问题就不在复现了。
综合上面测试结果可以基本排查是 vblank 除了问题,原因有两点:
- vblank 是硬件功能,出了问题重启窗管是恢复不了的;
- DRI2 送显也走 page flip ,也依赖 vblank 事件。
找出 kwin 卡在什么地方
所以接下来的分析重点就放在了 buffer 同步方面了。来本应该从 kwin 方面入手去分析,看它里面到底卡在了什么地方,为什么不再发送 present pixmap 请求, 但是我对的代码不了解,也不是很想碰, 所以我就想能不能找个简单 demo 程序分析 , 最后选用了 glxgears , 因为这个测试程序也是一个 Xclient ,也是使用 DRI3 渲染和 present pximap 送显,单独跑 glxgears 也会被卡住,也能复现这个问题, 而且代码逻辑相对 kwin 简单很多。
由于在 sw64 架构上不能使用 gdb 和 trace 工具,只能通过添加日志打印的方式调试 glxgears , 通过观察发现 glxgears 进程最后卡在了 glClear –> …. –> dri3_fence_await –> xshmfence_await
分析 xshmfence 工作原理
xshmfence 函数是由 libxshmfence1 这个包的代码提供,网上讲解 xshmfence 资料很少,根据 debian 上对 libxshmfence1 这个包介绍:
X shared memory fences - shared library
This library provides an interface to shared-memory fences for synchronization
between the X server and direct-rendering clients.
This package contains the xshmfence shared library.
从这段介绍可以大概知道 xshmfence_await 一种 X server 与直接渲染(准确的说是 DRI3 ) Clinet 直接共享内存资源同步的一种机制, 简单可以把他理解为一种进程间保护共享资源锁。把这个包的源码下载下来大概看了一下,关键 API 如下:
- xshmfence_alloc_shm : 分配一个 xshmfence 相关的文件描述符( fd )
- xshmfence_map_shm : 将一个文件描述于一个 xshmfence 关联, 主要是为了能在进程间共享,类似于 dma_buf 。
- xshmfence_trigger , 释放互斥 fence ,唤醒等待这个 fence 的所有进程,代码分析如下:
int
xshmfence_trigger(struct xshmfence *f)
{
if (__sync_val_compare_and_swap(&f->v, 0, 1) == -1) {
atomic_store(&f->v, 1);
if (futex_wake(&f->v) < 0)
return -1;
}
return 0;
}
__sync_val_compare_and_swap(&f->v, 0, 1) 语意:
当 f->v 等于 0 时, 将 f->v 赋值为 1 ,返回值为 0 , 不进 if 分支;
当 f->v 等于 1 时,返回值为 1 , 不进 if 分支;
当 f->v 等于 -1 时, 返回值为 -1 , 进 if 分支, 调用 atomic_store(&f->v, 1) 将 f->v 赋值为 1 ,在调用 futex_wake 唤醒所有等待这个 fence 的进程。
- xshmfence_await
int
xshmfence_await(struct xshmfence *f)
{
while (__sync_val_compare_and_swap(&f->v, 0, -1) != 1) {
if (futex_wait(&f->v, -1)) {
if (errno != EWOULDBLOCK)
return -1;
}
}
return 0;
}
__sync_val_compare_and_swap(&f->, 0, 1) 语意:
当 f->v 等于 1 时,返回值为 1 ,不进 while 循环
当 f->v 等于 0 , 将 -1 赋值给 f->v , 返回值为 0 , 进入 while 循环
当 f->v 等于 -1 ,返回值为 -1 ,进入进入 while 循环进入 while 循环:
调用 futex_wait 将当前进程挂起等待,直到有另外一个进程调用 futex_wake 将其唤醒
- xshmfence_resetvoid
xshmfence_reset(struct xshmfence *f)
{
__sync_bool_compare_and_swap(&f->v, 1, 0);
}
当 f->v 等于 1 时,将 f->v 赋值为 0
当 f->v 等于 -1 或 0 时,不做任何操作
找到调用 xshmfence_trigger 和 xshmfence_reset 的地方
xshmfence_trigger 调用是在 Xorg 进程里面,调用路径:
proc_present_pixmap --> ... miSyncShmFenceSetTriggered --> xshmfence_trigger
xshmfence_reset 调用也在 glxgears 进程里面,调用路径:
draw_frame --> glXSwapBuffers --> ... --> dri3_fence_reset --> xshmfence_reset
汇总分析
1)xshmfence_await 调用路径
glClear –> …. –> dri3_fence_await –> xshmfence_await
在 glxgears 渲染开始,准备 buffer 阶段。
2)xshmfence_trigger 调用路径
drmmode_notify_fd–> … amdgpu_drm_queue_handle_one –> … miSyncShmFenceSetTriggered –> xshmfence_trigger
在 xorg 接收到内核上报上来的 vblank 事件处理过程中, 这个过程在 glxgers 发送的 present pixmap 强求之后,在 amdgpu_drm_queue_handle_one 中会将 glxgers 发送 pixmap 数据拷贝对应窗口 buffer 中, 让后调用到 xshmfence_trigger 与 glxgears 同步 pixmap buffer 已释放。
备注:Xorg⾥⾯本来还有⼀出调⽤到xshmfence_trigger, 这个路径是present_scmd_pixmap – > present_pixmap_idle –> … –> xshmfence_trigger , 这个是旁⽀ ,注释掉了之后不会影响到显⽰功能, 而而且问题可以照样复现,这样就保证Xorg⾥⾯只有上⾯⼀处调⽤到xshmfence_trigger
3)xshmfence_reset调⽤路径
draw_frame –> glXSwapBuffers –> … –> dri3_fence_reset –> xshmfence_reset glxgears进程在渲染完⼀帧数据,然后调⽤glXSwapBuffers, glXSwapBuffers⼜会调⽤ xcb_presetn_pixmap ,将这⼀帧数据发送给xorg送显, 在xcb_presetn_pixmap之后会调⽤到 xshmfence_reset。
经过代码查看,整个系统中有且只有上⾯三处分别调⽤到这三个接口, 为了验证这⼀点,我⽤bpf的 uprobe跟踪验证过,验证⽅法如下:
sudo bpftrace -e 'u:/usr/lib/x86_64-linux-gnu/libxshmfence.so.1:xshmfence_reset {printf("%s, %d\n", comm, pid);}'
sudo bpftrace -e 'u:/usr/lib/x86_64-linux- gnu/libxshmfence.so.1:xshmfence_trigger {printf("%s, %d\n", comm, pid);}'
sudo bpftrace -e 'u:/usr/lib/x86_64-linux-gnu/libxshmfence.so.1:xshmfence_await {printf("%s, %d\n", comm, pid);}'
根据上述整理,以上调⽤时序如下:
⾸先,glxgears 进程先调⽤xshmfence_await
然后,Xorg进程调⽤xshmfence_trigger
最后,glxgears进程再调⽤xshmfence_reset
正常情况下⼀直按照这个时序循环往复下去,为了更直观的看这个过程,加了如下打印:把Xorg⾥⾯ present模块⽇志打卡在xshmfence_await 、xshmfence_trigger、xshmfence_reset 函数调⽤⼊口和退出的地⽅将f->v的值、f的地址、以及时间戳打印, 另外将mesa中把调⽤xcb_presetn_pixmap的传参 pixmap 的id和windows id打印出来, 这样就可以判断这个循环往复的过程是那⼀次。
按照上述添加的打印,复现内容是的⽇志如下:
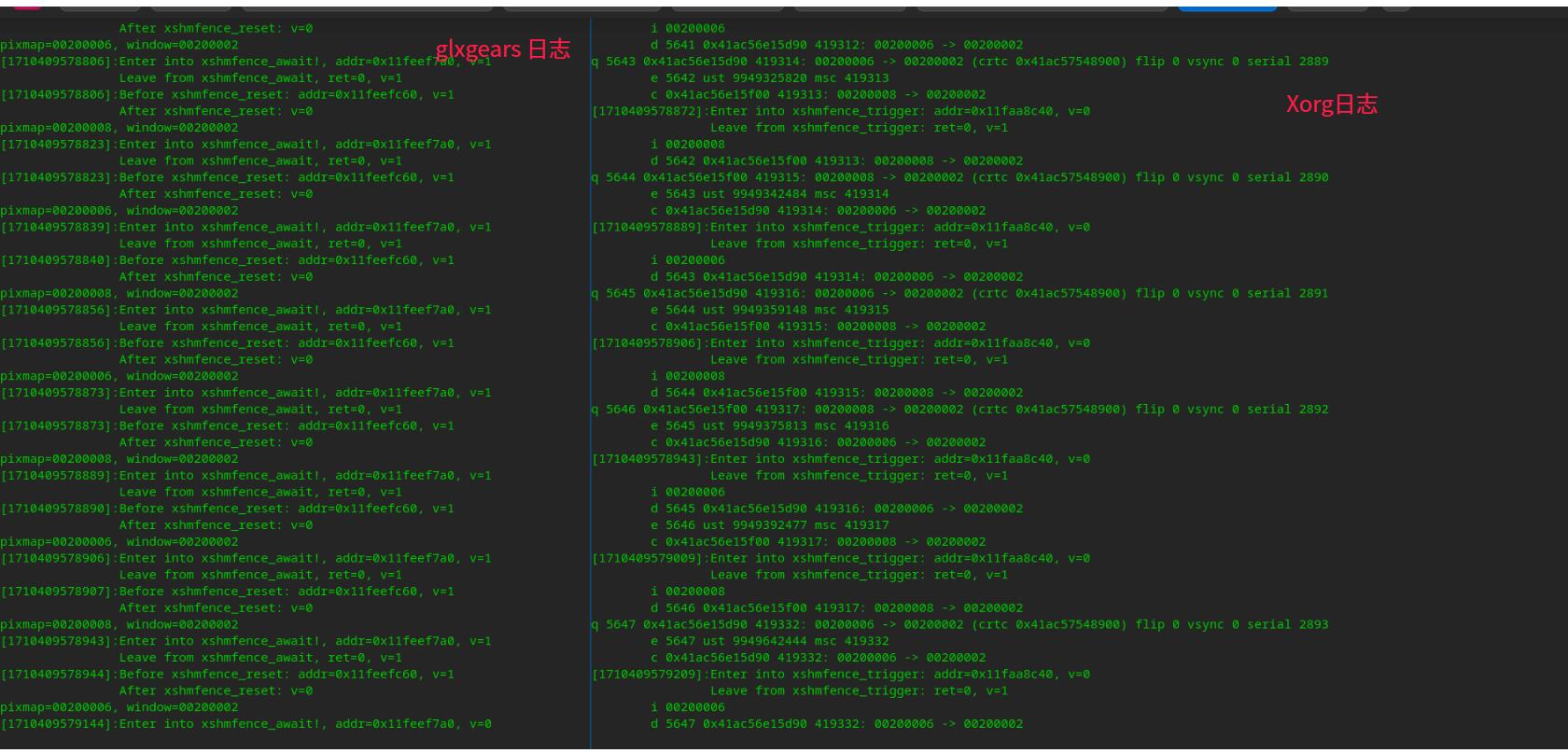
从最后5帧送显分析起:
pixmap=00200006
1710409578872: xshmfence_trigger v: 0 --> 1
1710409578873: xshmfence_await v: 1 --> 1
1710409578873: xshmfence_reset v: 1 --> 0
pixmap=00200008
1710409578889: xshmfence_trigger v: 0 --> 1
1710409578889: xshmfence_await v: 1 --> 1
1710409578890: xshmfence_reset v: 1 --> 0
pixmap=00200006
1710409578906: xshmfence_trigger v: 0 --> 1
1710409578906: xshmfence_await v: 1 --> 1
1710409578907: xshmfence_reset v: 1 --> 0
pixmap=00200008
1710409578943: xshmfence_trigger v: 0 --> 1
1710409578943: xshmfence_await v: 1 --> 1
1710409578944: xshmfence_reset v: 1 --> 0
pixmap=00200006
1710409579009: xshmfence_trigger v: 0 --> 1
1710409579144: xshmfence_await v: 0 --> .... 卡住没有出来 ,此时调⽤
__sync_val_compare_and_swap(&f->v, 0, -1)后v的值应该变为1
1710409579209: xshmfence_trigger v: 0 --> 1
glxgears挂起在xshmfence_await,没有 调⽤到xshmfence_reset,v的值应该保持为1
从上⾯的信息来看,时间在1710409579144时glxgears 进程调⽤到xshmfence_await, 此时v的值为0 ,调⽤完__sync_val_compare_and_swap(&f->v, 0, -1)后v的值应该变为-1, 然后再⽤到futex_wait, glxgears进程被挂起, 最后时间在1710409579209时,Xorg进程调⽤xshmfence_trigger,调⽤次函数前v值应该为-1,如果是这种情况,xshmfence_trigger应该将v赋值为1,然后继续调⽤futex_wake唤醒 glxgears进程,此后循环仍然可以继续走下去, 但是问题出在Xorg进程调⽤xshmfence_trigger前的v的值变成了0,这是再调⽤到xshmfence_trigger时,就不会执⾏到futex_wake唤醒glxgears进程, 这样 glxggears就不会继续往下走,不会再调⽤xcb_present_pixmap 向Xorg送显, Xorg这边也再也执⾏不到xshmfence_trigger这⾥,所以glxgears就⼀直卡住了。
综上分析,问题就出glxgears在最后⼀次调⽤xshmfence_await, v的值应该变为-1 ,⼀直到Xorg调⽤ xshmfence_trigger 是都v的值应该保持为-1,但是实际情况 确实不知道什么时候v的值莫名其妙的变成了0, 难道是xshmfence_await没有将v的值改为-1, 为了确认这个事情我⼜在xshmfence_await加了⼀句打印,代码如下:
int xshmfence_await(struct xshmfence *f)
{
struct timeval tv;
gettimeofday(&tv, NULL);
fprintf (stderr, "[%ld]:Enter into xshmfence_await!, addr=%p, v=%d\n", get_time_ms(), &f, f->v);
while (__sync_val_compare_and_swap(&f->v, 0, -1) != 1) {
fprintf(stderr, "\t\t xshmfence_await -- > futex_wait, v=%d\n", f->v);
if (futex_wait(&f->v, -1)) {
if (errno != EWOULDBLOCK){
fprintf (stderr,"\tLeave from xshmfence_await, ret=-1, v=%d\n", f->v);
return -1;
}
}
}
fprintf (stderr,"\t\tLeave from xshmfence_await, ret=0, v=%d\n", f->v);
return 0;
}
测试结果:
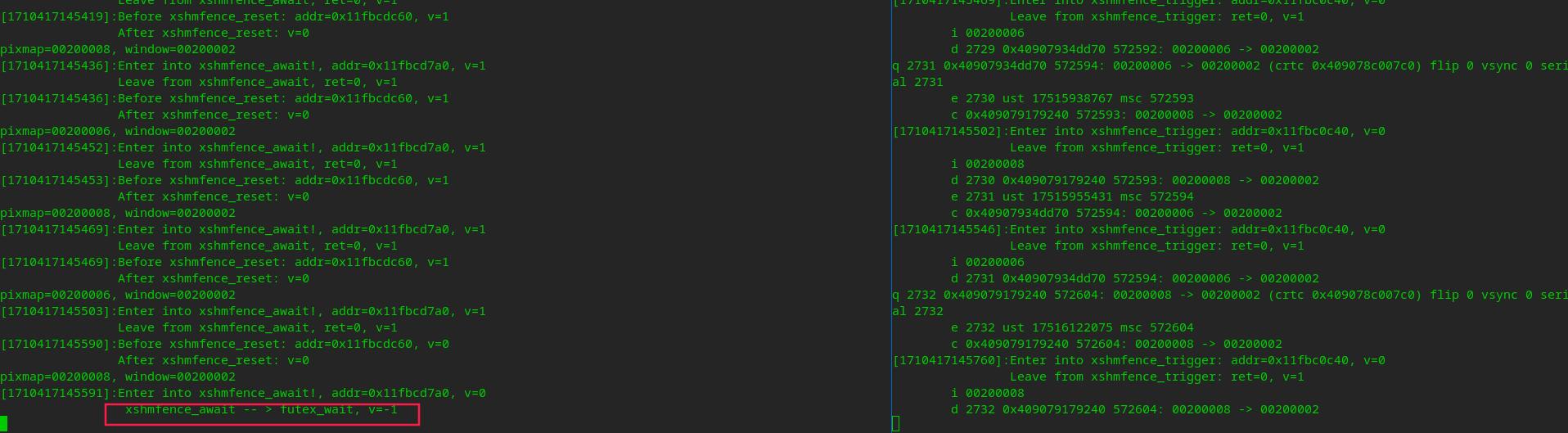
结果令⼈很失望,xshmfence_await 在执⾏futex_wait挂起glxgears之前,成功的把v的值改成了-1。 那会是在什么地⽅将v的值⼜变成了0呢?
还有⼏个换⼀点,会不会是有重新调⽤到初始化流程那⾥了呢?我⼜⽤bpf uprob 跟踪了⼀下 xshmfence_alloc_shm、xshmfence_map_shm,在glxgeas运⾏运⾏起来后就整个系统上就再也没有运⾏这两个函数了, 这下我就侧底被整懵了!!!
到此为⽌暂时没有什么快捷的办法定位这个问题了,后⾯要继续分析就得从xshmfence在内核⾥⾯实现机制进⾏研究了,包括如下⼏点:
1.Xorg ⾥⾯⼀种通过共享⽂件描述符的⽅法,⽐如Xorg这边打开⼀个⽂件,得到⼀个⽂件描述符,它可以通过socket将这个⽂件描述符传给glxgears那边, 然后glxgears那边拿到这个⽂件描述符后可以直接操作这个⽂件。 prime buff就是通过这种放⼤实在Xorg和Xclient直接共享的, 现在 xshmfence也⽤到这个机制,Xorg这边调⽤xshmfence_alloc_shm创建⼀个⽂件描述符,通过这种机制共享给glxgeras ,两边都可以通过xshmfence_map_shm 映射这个fd得到⼀个 xshmfence, 虽然这个xshmfence在不同的地址空间⾥⾯,但是实际指向的是同⼀个东西,所以⼀个进程修改了f->v 的值也应该⾥⾯传导到另⼀个进程, 而现在出问题了时貌似这个值没有传导过去 ,所以⾸先看看这两个地⽅的fd 是不是指向同⼀个inode
2.如果两边的fd是指向同⼀个inode, 那么f->v 对应的是内核⾥⾯那⼀块内存,⼀个进程修改之后会不会传导到另外⼀边共享它的进程中去。
后人分析
问题现象:
Sw831 机器 ltp 压测时,桌面环境卡死,但是内核正常运行,dmesg 未报错误。重启 kwin 或者 lightdm 可以恢复桌面。
现象分析 1:
从现象来看像是一个桌面环境的软件 bug,桌面环境分析可以参考@胡晓东 的分析文章, 大致内容如下:
Xserver 和 client 使用共享内存通信(共享库 libxshmemfence),在压测时服务端往共享内存 v 里写了 1,但是客户端里读取出来的是 0。通过调试没有发现没有其他进程去修改这个值。 使用的是__sync_val_compare_and_swap 进行修改共享变量的值,所以怀疑是没有保证一致性才导致的 bug 产生。
现象分析 2:
关闭 swap,ltp 压测时桌面环境正常运行,怀疑是和 swap 有关,为了验证共享内存和 swap 之间的关系,将共享内存使用 mlock 锁住,在压测的时候不让其交换到 swap 里,桌面环境在 ltp 压测时可以正常运行。

进一步排查是不是交换的问题,代码改造如下:在出问题的时候循环读取变量值,发现是 0 就改成-1, 过一会后再读取,发现值又被改成 0 了, 说明内容一直被改,关闭 ltp 就不会被改了,进一步说明是 swap 的过程中导致这个内存的内容被改了。
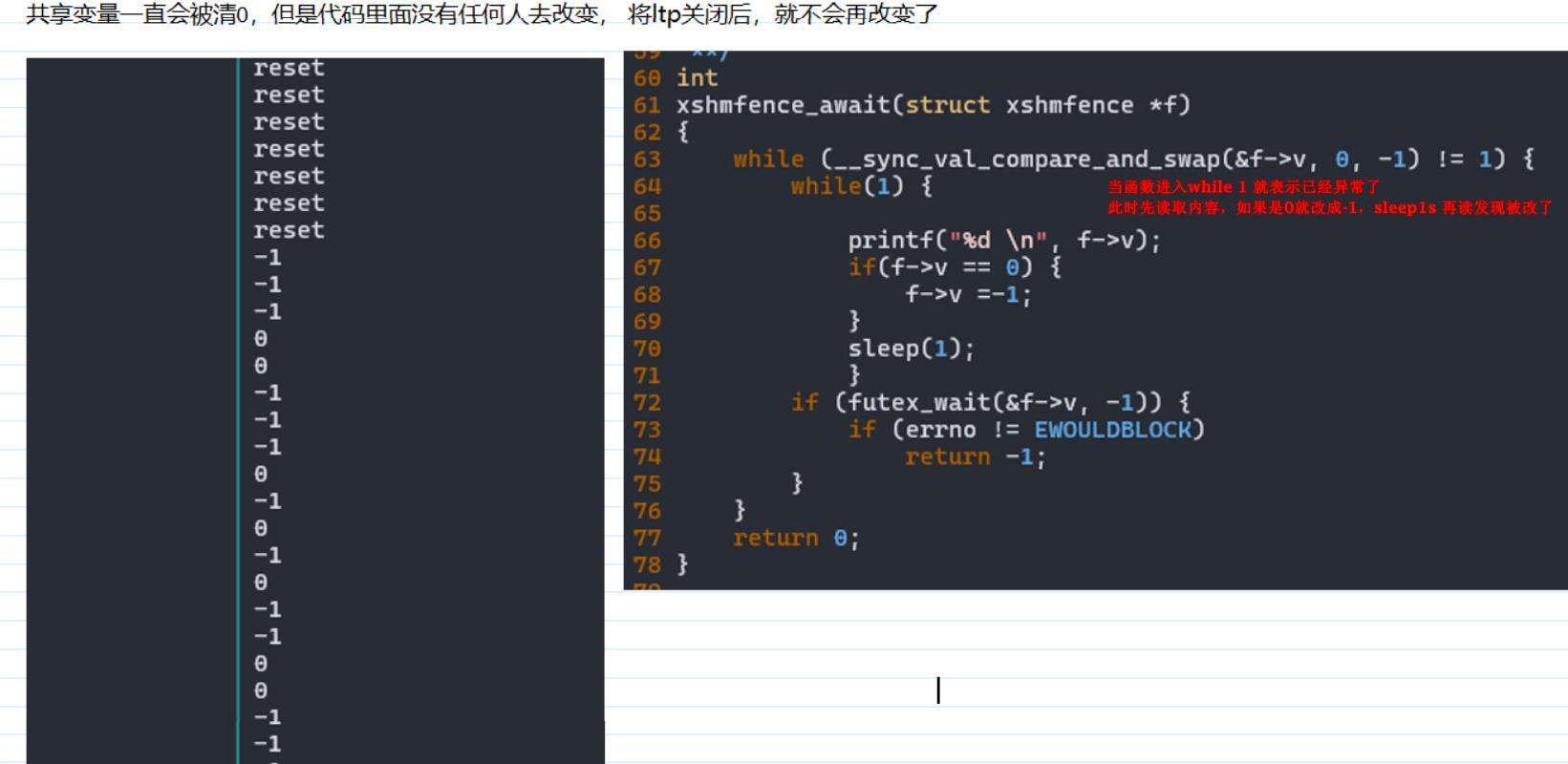
通过关闭 swap 或者关闭 ltp 可以防止共享内存数据丢失,猜测两种可能
1、 swap in 的时候读取数据出错,
2、 swap out 的时候数据没有及时写入
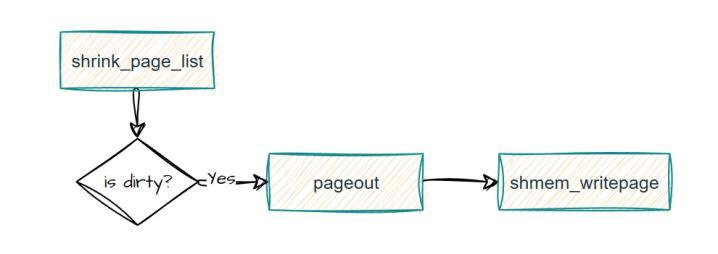
swap in 路径是 page fault,
swap out 是通过 add_to_swap 、shmem_writepage 、swap_writepage。
对 swap in ,swap out 的关键路径进行埋点,发现 swap in 的时候 触发 page fault 是直接去申请新的内存,而不是去从 swap cache 中找对应的 entry, 且 swap out 的时候也没有将共享内存移动到 swap 里去,原因是因为共享内存所在的 page 不是 dirty,所以没有被写入到 swap 中(shmem_writepage 的实现就是将共享内存移动到 swap 中)

所以问题的大概原因是:xserver 往共享内存写 1,然后 ltp 测试时内存不够用了共享内存需要被回收到 swap 里,但是共享内存的 page 不是 dirty 所以直接丢弃了,client 在访问地址时触发 pagefault 在 swap cache 中找不到所以直接申请了一个新的,所以 client 读取的数据是 0。
这里就很奇怪,打印 page 的内容发现数据是 1,也就说明 xserver 成功将数据写入到内存里, 但是 page 的 flags 不是 dirty???
为什么页没有被置为 dirty?
访问共享内存的地方只有 gcc built-in 函数__sync_val_compare_and_swap ,原理是先比较共享内存 v 的值是不是预期值,如果是就写入一个新的值;
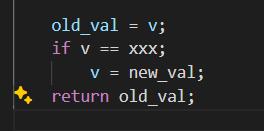
在 do_page_fault 时,访问共享内存只有 FAULT_FLAG_READ 而不是 FAULT_FLAG_WRITE, 所以对应的 page 不会被设置 dirty 标志。
为什么第一次通过 read 触发 fault,后续通过 write 写入内存,page 不会被置为 dirty, 其他架构时怎么做的?
Arm64: 这种共享内存方式,arm 读会触发 pagefault,写会再次触发 pagefault。
X86: x86 也只会触发一次 pagefault, 但是第一次 page fault 的时候就是 write 标志, x86 的汇编如下,不知道为什么 mov 没有触发 read 而是 write

如果 x86 先触发 read ,再触发 write 会不会有 bug?
我将代码改造了一下:
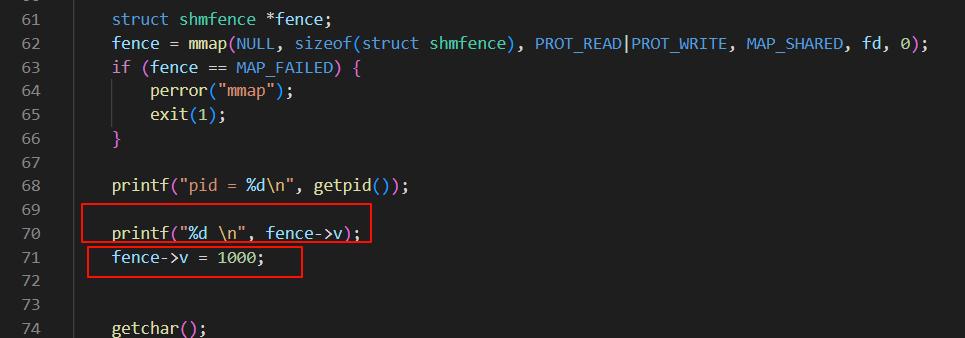
先使用 read 触发 fault,再往里面写入一个值,通过 bpf 可以观察到也只有一次 page_fault , 而且 flags 也是 READ,但是第一次 page fault 后,共享内存的 pte 会被置为 dirty ,这个 dirty 是继承的 vma->vm_page_prot(而 sw64 没有)

由于 pte 的 dirty 是 1, 所以再 umap 或者其他流程会通过 pte dirty 来改变 page 的 dirty 位。
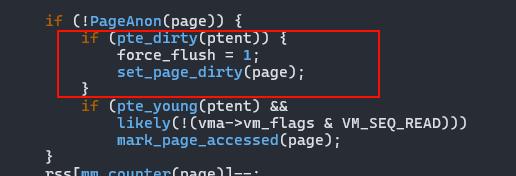
Vma flags 是通过 arch 层做了转换

解决方案
1、 修改 vma_page_prot flags 不稳定,会导致其他问题。
2、 因为 xorg 使用共享内存都是通过 gcc built-in 函数访问,可以首次先写入一个值触发 page_fault 让它的 page 有 dirty 标志位,可以解决问题。
总结:
对于这种共享内存,先 read 触发 page fault,再写入内容,x86 第一次就会将 pte 设置为 dirty,后续 page 会因为 pte dirty 而被置为脏页。 Arm64 则会触发两次 page fault,第一次 read、第二次 write fault,在第二次时会将 page 标记为脏页。
而 sw64 在访问这种共享内存时先读后写只会触发一次 page fault,且 pte 还没有被置为脏所以在这种情况下会存在页无法被写回的 bug。