
王昱力同学追踪的问题,从他的详细说明中我们可以看到,SOC 的设计有着细节上的缺陷是很正常的。估计就是 A 卡驱动的工程师默认中断的速度小于 DMA 的速度。而在某些情况下,这个情况不成立了,那么就迎来了 bug 。关键是这个问题是如何分析出来的呢?这种问题需要用专用的硬件设备看寄存器的状态吗?我觉得是不需要的。因为有很多上游的问题分析并不是龙芯官方绐出的,而其它人怎么会单独为了龙芯买昂贵的 ejtag 呢?
所以别人能分析出来,我也没有道理分析不出来。别人能快速找到问题的原因还是在于经验,而这些经验可能没有人去教需要自己花时间积累和总结。
前情提要
经社区反馈,龙芯机器使用AMD GCN 2.0(如 R7 360)、GCN 3.0(如 R9 Nano)及 GCN 4.0 (如 RX 400/500 系列及 WX 2100/3100/4100/5100/7100)架构显卡且有高图形负载(如 3D 游戏和高清视频)时偶发驱动复位和桌面重启等不稳定现象。
必现方式:在内存足够(防止oom)的龙芯机器上同时开32个glmark, 机器将很快卡死,dmesg中出现amdgpu相关报错。复现场景包括3a5000和3a6000,也不区分新世界旧世界,不论任何内核版本和发行版,均可以复现问题。
Linux 下测试的方法是 for i in `seq 1 32`; do glmark2 –run-forever & done,如果在运行时随意拖动或切换窗口,很容易可以触发;使用有显卡加速的浏览器看 4K 视频也能很快复现。
实验现象:通过关闭 amdgpu 的动态电源管理 (amdgpu.dpm=0) 可以极大程度缓解这个问题,但这个参数会导致在很多显卡上锁低频率运行,性能非常差。
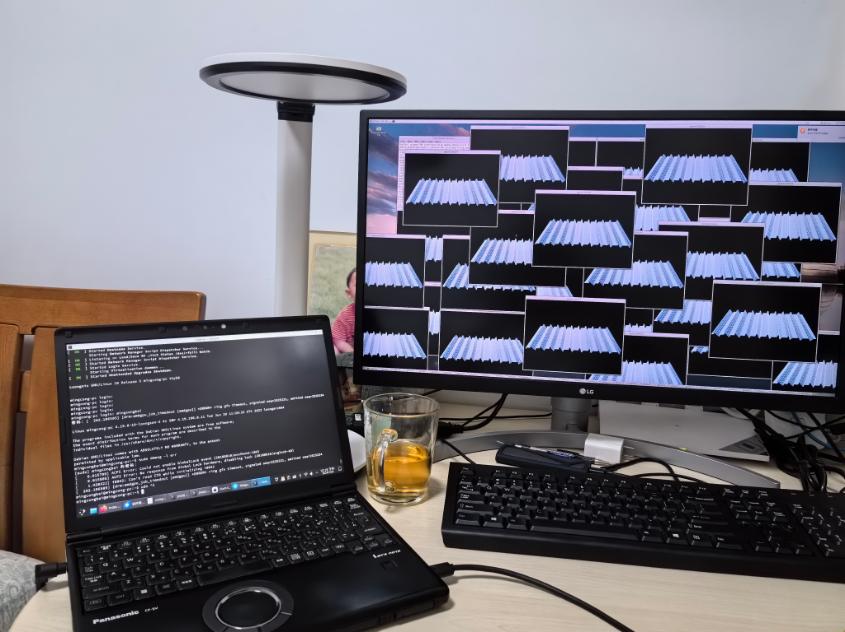
后来通过观察显卡状态,发现 amdgpu 驱动在开了 dpm 的时候,PCIe 是会根据负载重新协商 PCIe 版本,似乎在协商频率比较高的时候会触发显卡的 ring gfx timeout 错误(可以理解成驱动的 IRQ 没有正确处理,导致超时),随后驱动会尝试复位——最后桌面会崩溃重启。
后来换用 RX 7600 这款 PCIe Gen 4 的显卡进行测试,这张卡有个特点是,就算打开了 dpm 也不会根据负载调整 PCIe 版本,这张显卡是不会出现任何崩溃复位问题的。
此外,经过尝试,在 7A 桥片上挂个风扇,发现在不关闭 dpm 的情况下,问题出现的时机延后了很多。
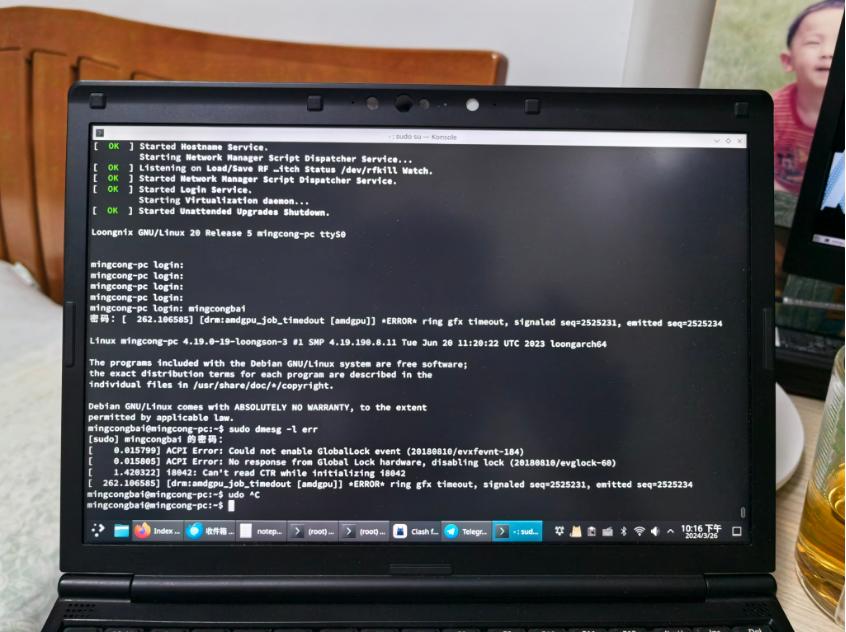
但是,唯独在UOS专业版无法复现该问题。
波及范围
AMD Radeon 系列:
·HD7790, HD8770
·R7 260, R7 260X, R7 360
·R9 285, R9 285X, R9 290, R9 290X, R9 295X2, R9 360, R9 380, R9 380X, R9 390, R9 390X
·R9 Fury, R9 Fury X, R9 Nano
·RX 455, RX 460, RX 470, RX 470D, RX480
·RX 540, RX 550, RX 550X, RX 560, RX 560D, RX 570, RX 580, RX 590, RX 590 GME
·530, 530X, 535, 620, 625, 630, 640
AMD FirePro 系列:
·S7100X, S7150, S7150 X2
·S9100, S9150, S9170, S9300 X2
·W4300, W5100, W7100, W8100, W9100
AMD Radeon Pro 系列:
·WX 2100, WX 3100, WX 3200, WX 4100, RX 5100, WX 7100, WX 8200, WX 9100
·Duo, SSG
实际上,GCN 1.0系列显卡(如 R7 240)也受此问题影响,但造成问题的原因可能不同。
技术分析
我们在 Linux 内核相关支持代码中发现,AMD 在 2015 年分别引入的 amdgpu gfx7/cik (GCN2) 支持 ¹ 及 gfx8 (GCN4) 代码 ² 中分别包含同样的规避性代码,在写入内存及发出中断请求前执行了额外的 EVENT_WRITE_EOP (Write and End-of-Pipe) 指令重复写入内存,以期解决一处(AMD 完全没有进行解释的)潜在硬件问题。
这一修复在搭载龙芯 7A 桥片的龙架构上产生了副作用:两次额外的写操作在已知中断请求及 DMA 数据处理顺序有概率发生错误 ³ 的龙芯 7A 桥片上可能造成数据不一致问题,进而导致先前遇到的驱动超时、崩溃及复位问题。
为此,社区维护者郑兴达针对 gfx7 及 gfx8 架构显卡编写了两个补丁 ⁴,在保持两次写入的规避代码的设定下,让两次写入的数据保持一致,规避龙架构上可能发生数据不一致的问题。
———
¹ AMD 在 amdgpu[1] 及 radeon[2] 内核模块针对 gfx7/cik (GCN 2.0/3.0) 架构显卡的规避补丁
² AMD 针对 gfx8 (GCN 4.0) 架构显卡的规避补丁[3]
³ 从龙芯中科陈华才老师针对7A 桥片平台的 radeon 内核模块的修复[4]说明可见,7A 桥片中断请求及 DMA 数据处理顺序有概率出现问题
⁴ 郑兴达针对 amdgpu[5] 及 radeon[6] 内核模块的修复补丁
参考资料
[3] gfx8 (GCN 4.0) 架构显卡的规避补丁: https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=bf26da927a1cd57c9deb2db29ae8cf276ba8b17b
[4] 针对7A 桥片平台的 radeon 内核模块的修复: https://github.com/chenhuacai/linux/commit/da63bd7429f2bb7ce7988a95d125f50426466555
[5] amdgpu: https://github.com/AOSC-Tracking/linux/commit/1d0e4bb75b29ef80b7129d76c9a0609d9b912eeb
[6] radeon: https://github.com/AOSC-Tracking/linux/commit/c7772bb8b1a27d59bbb32ef8612a9a41fecb6410
总结
综上所述,UOS专业版没有问题的原因也找到了:我们专业版内核的代码基线在4.19.90小版本,上述引发问题的提交还没有合 入,我们因版本过低而不受影响。
虽然我们发现了是哪笔提交引入的问题,但是其实并不明白其背后的原理。比如:为什么会引发问题?为什么只会在龙芯的机器上引发问题?revert该提交会对amdgpu本身以及其在其它架构的行为上产生哪些影响?
其实这都是未知数。
因此将该阶段性分析成果分享给各位同事,不知道各位大佬们有没有更多的思路和见解。