
将 pdf 文件直接嵌入到博客当中
b 站,油管上的 crash 的视频有很多。但是不如同事总结的更实用一些。为了方便将 pdf 类型的 ppt 直接放到我的博客当中,参考了下面的两篇文章。
https://cosimameyer.com/post/embed-your-slides-hugo-blog-post/
https://ox-hugo.scripter.co/doc/shortcodes/
我是可以直接把 b 站中的视频放到这里面的。
{{< slideshow “https://r2.guolongji.xyz/vmcore%E7%9A%84%E8%A7%A3%E6%9E%90.pdf” >}}
目标是输出这样的一个格式。
- 使用 hugo 自带的宏
@@hugo:\{\{< slideshow "https://r2.guolongji.xyz/vmcore%E7%9A%84%E8%A7%A3%E6%9E%90.pdf" >\}\}@@
还有一篇相似的文档可以看:
https://r2.guolongji.xyz/crash%E5%88%86%E6%9E%90vmcore%E5%85%A5%E9%97%A8.pdf
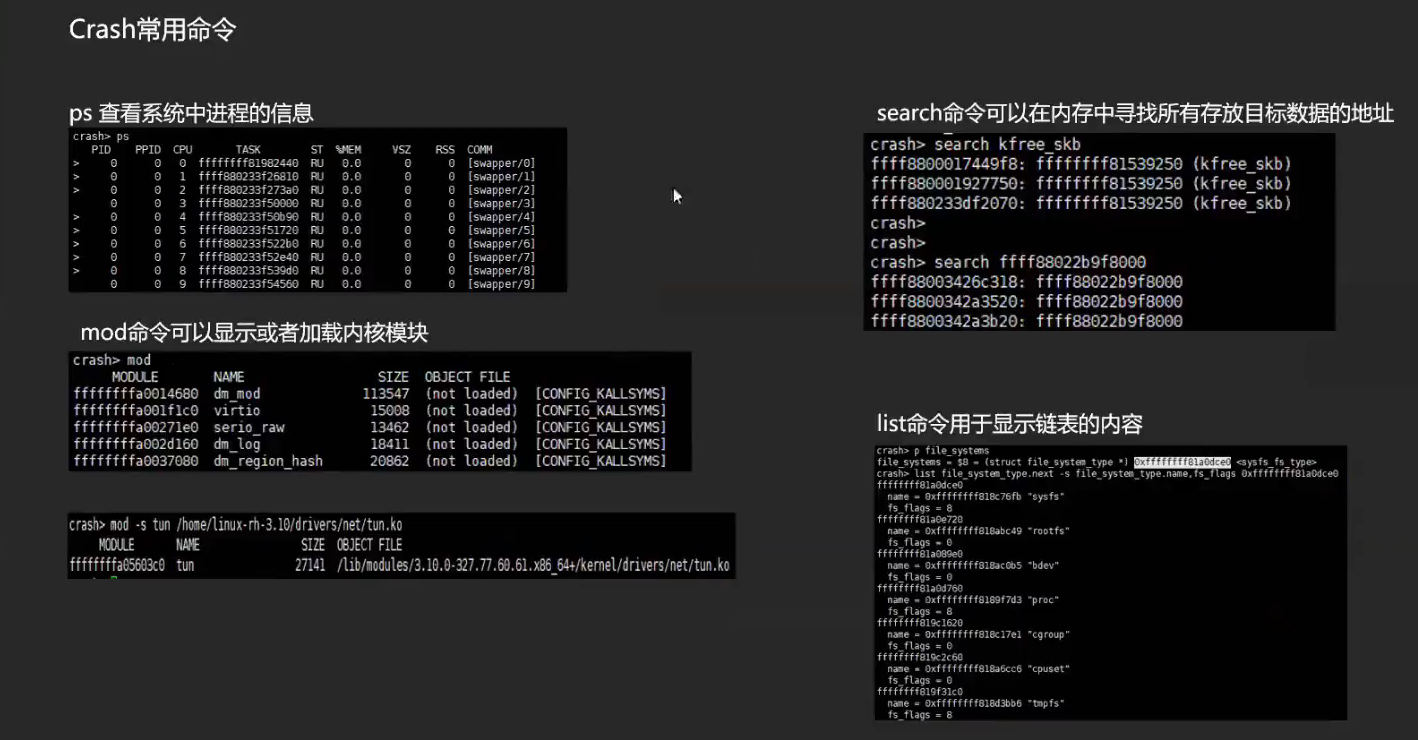
crash 的使用
crash search
- 补充一下 crash 当中 search 的使用:https://www.cnblogs.com/pengdonglin137/p/16320758.html
用法:
- 设置搜索的起始地址,可以配合下面的-k -u -p等使用
search -s <起始地址>
- 搜索内核虚拟地址空间,这个也是默认的搜索选项
search -k
- 搜索内核虚拟地址空间,但是会排除vmalloc区、内核模块区以及mem_map区
search -K
如果想进一步排除unity-mapped、内核代码和数据段,可以使用search -V
在当前进程的用户虚拟地址空间搜索
search -u
- 在物理内存地址中搜索
search -p
- 在每个进程的内核栈里面搜索
search -t
比如可以用来搜索锁被哪些进程持有,那么可以在进程的内核栈里搜索锁的地址
- 在当前正在运行的进程的内核栈里面搜索
search -T
- 设置搜索的结束地址
search -e <结束地址>
- 设置搜索的空间长度
search -l <长度>
- 设置屏蔽位,即搜索时不比较被屏蔽的位,比如设置为0xFFFF0000,表示只比较低16位
search -m <屏蔽掩码>
比如:search -p babe0000 -m ffff -w
- 搜索字符串,如果字符串中间有空格,需要用"“将整个字符串括起来
search -c <字符串>
比如:search -c “can’t allocate memory” “Failure to”
- 按32位搜索,这个功能只在64位系统上有效,这样可以分别比较高32和低32位
search -w
- 按16位搜索
search -h
- 当匹配到的时候,在显示时输出匹配到的地址前后一部分内存数据,这里的数量的的单位是被搜索的内容的大小
search -x <数量>
- 搜索表达式的值
search (__down_interruptible+191)
关于踩内存
crash vmcore 的分析常用手段是找堆栈找到出错的现场。如果是地址异常,可以用 search 命令来找其它的内核进程是不是还在,如果还在的话,问题就很好定位了。如果不在的话,就要看代码来解决问题。通过代码的关键分支,来白盒测试验证问题是否得到了解决。这个是内核定位问题的一个终极解法。
最最关键的问题,还是对于上下文流程和这个问题涉及的子系统有足够的了解。
openeuler 的两个 crash 问题举例
https://www.bilibili.com/video/BV1mQ4y1Z7BQ/?spm_id_from=333.337.search-card.all.click
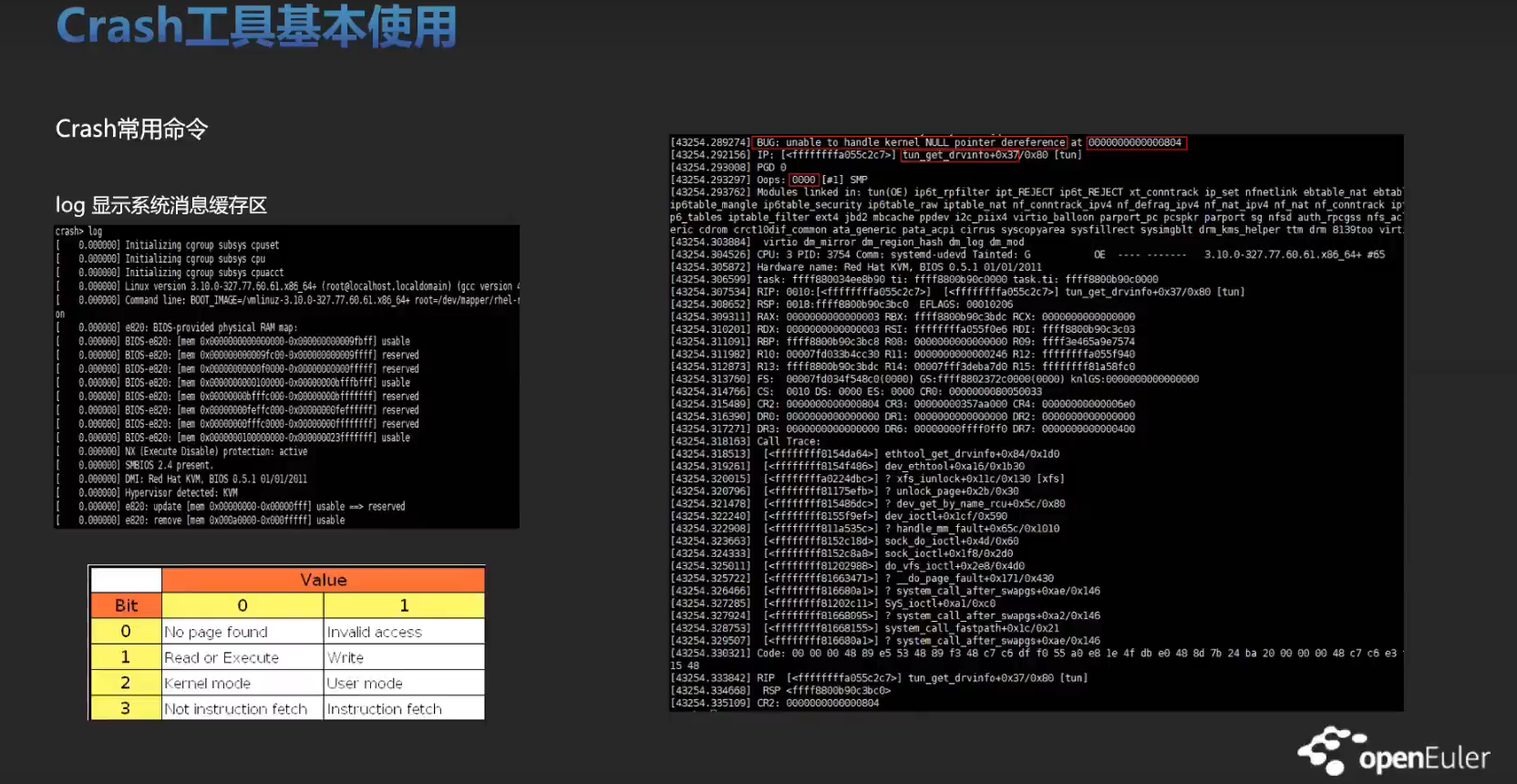
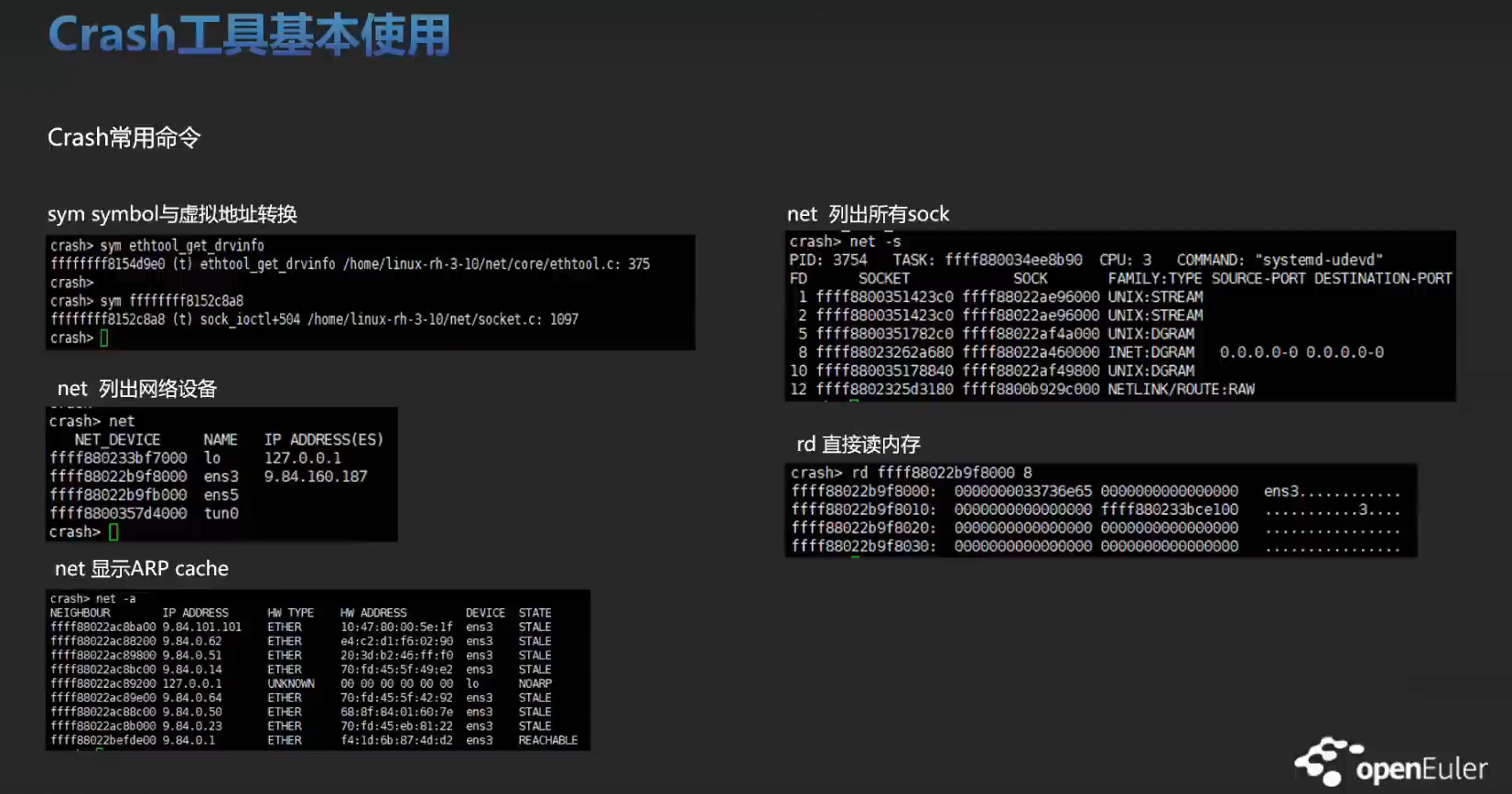
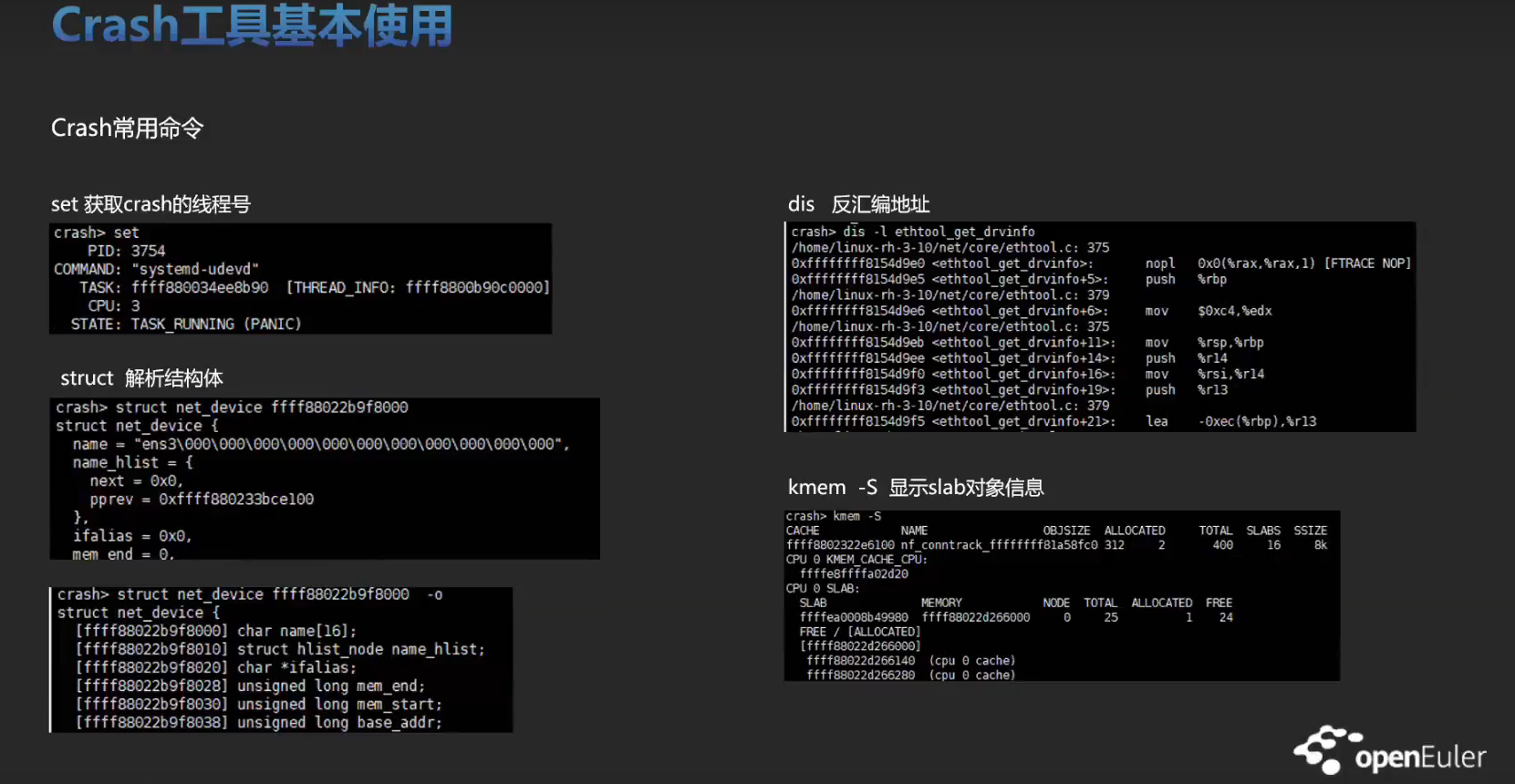
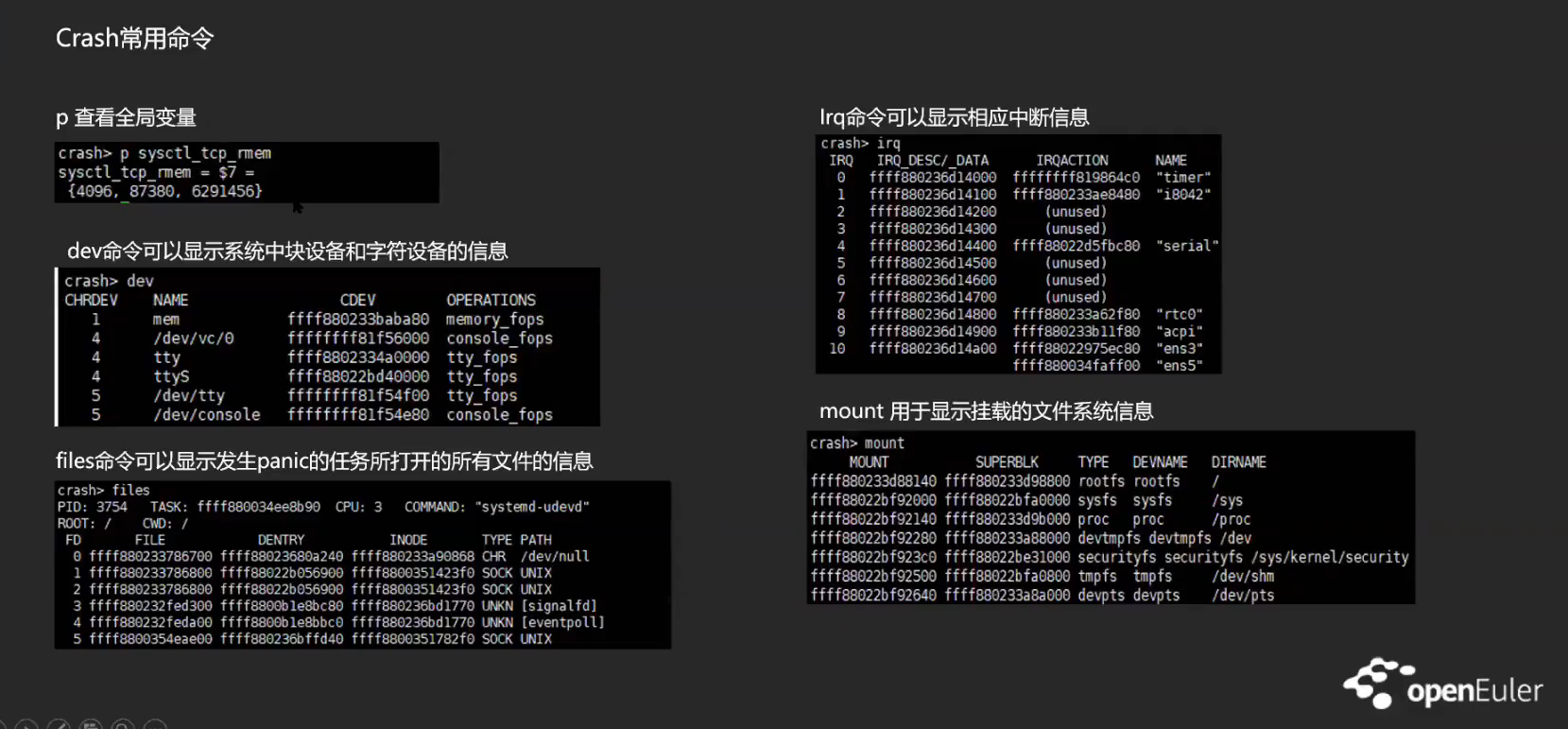
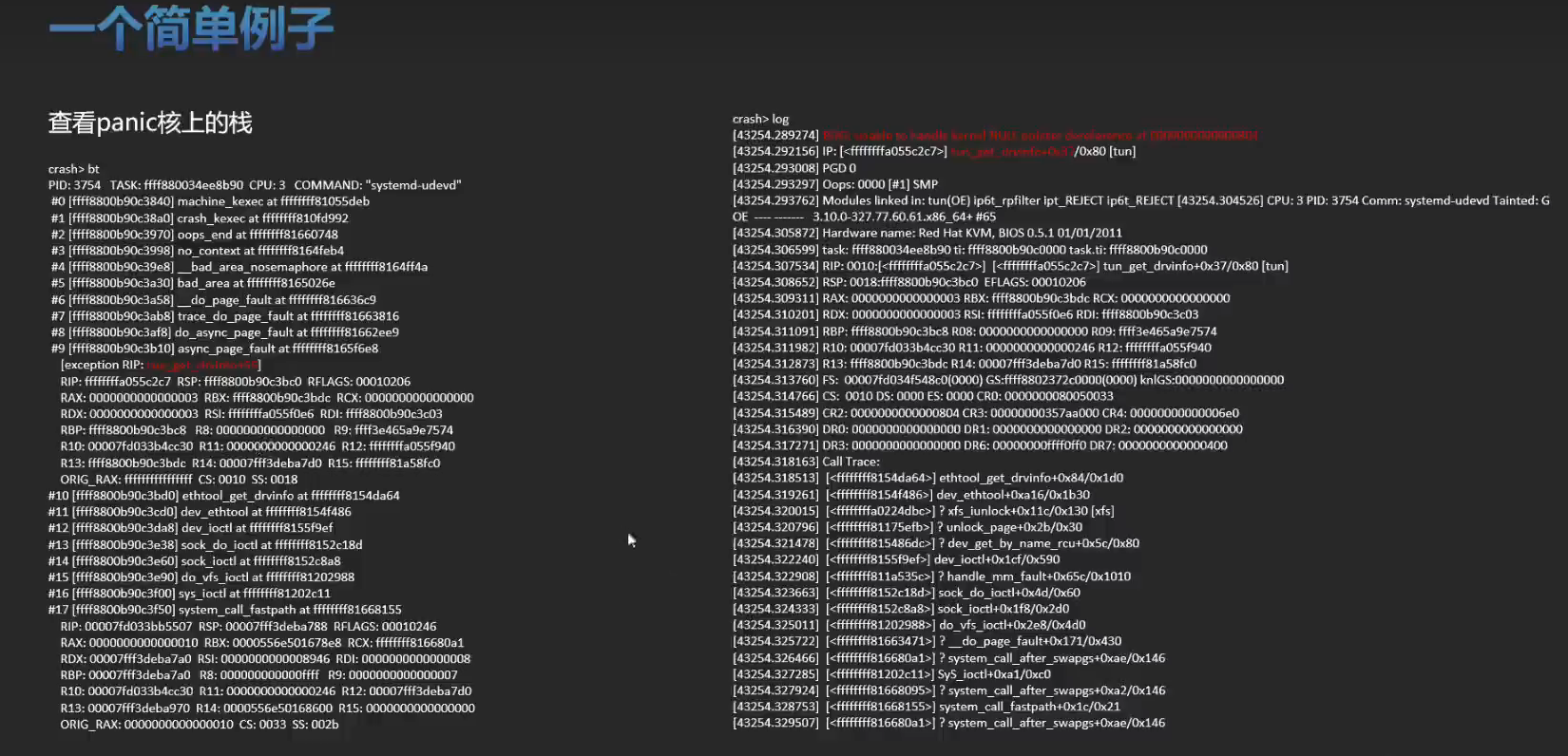
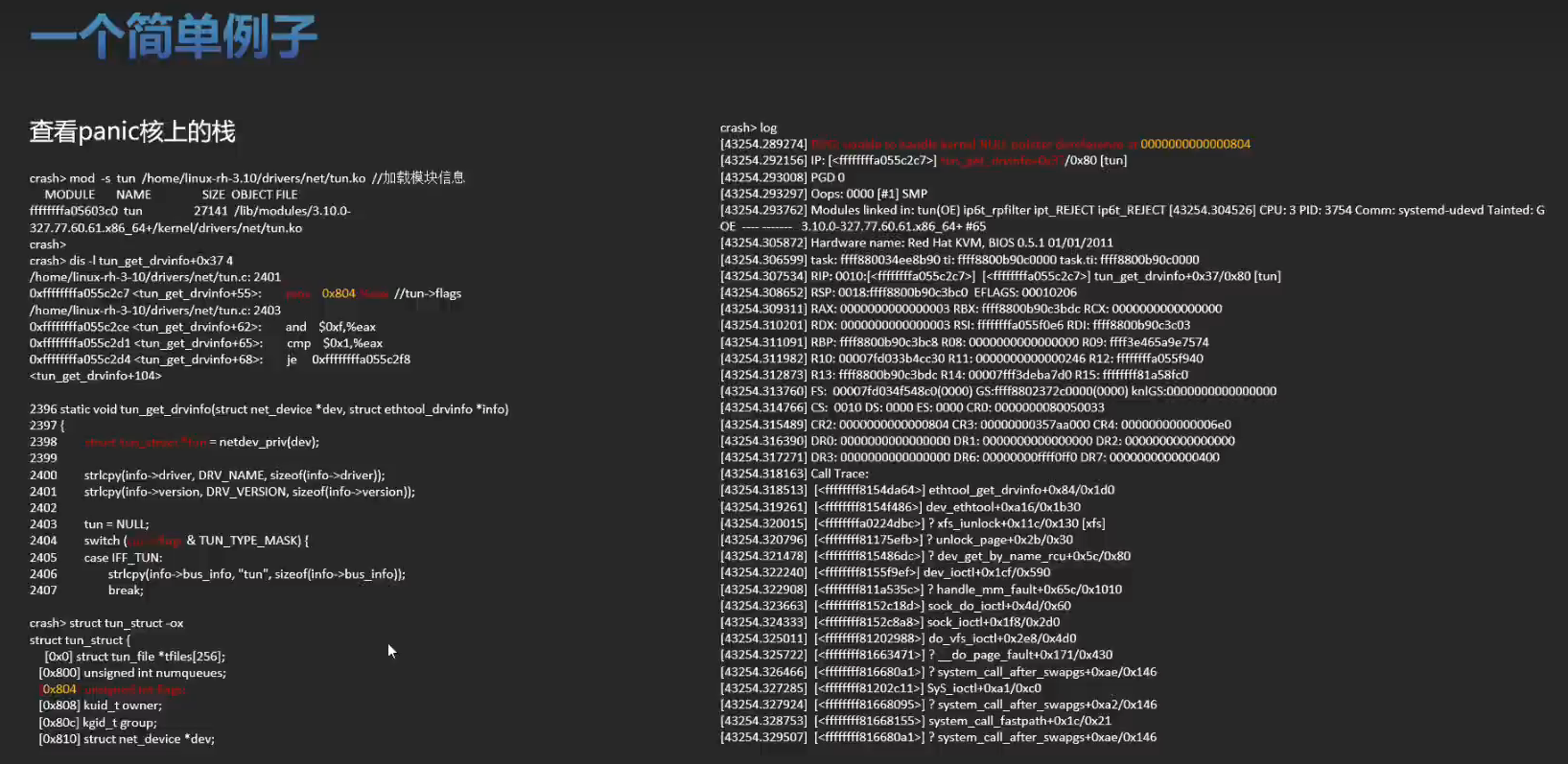
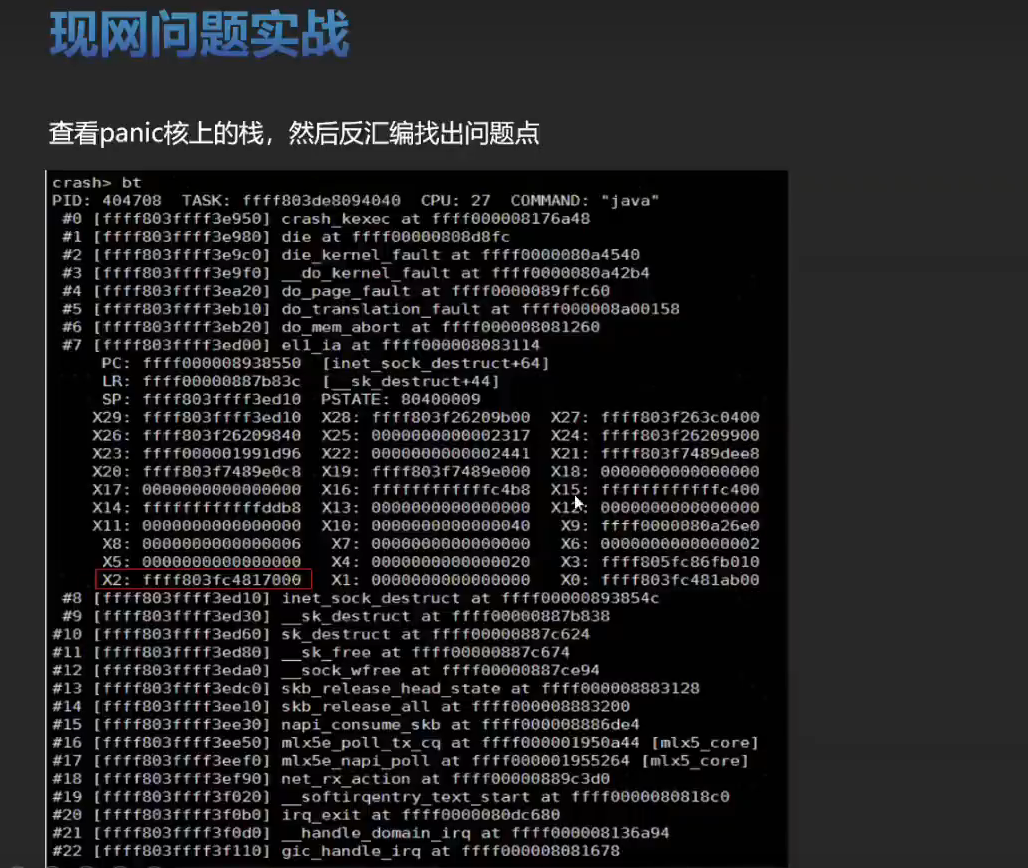
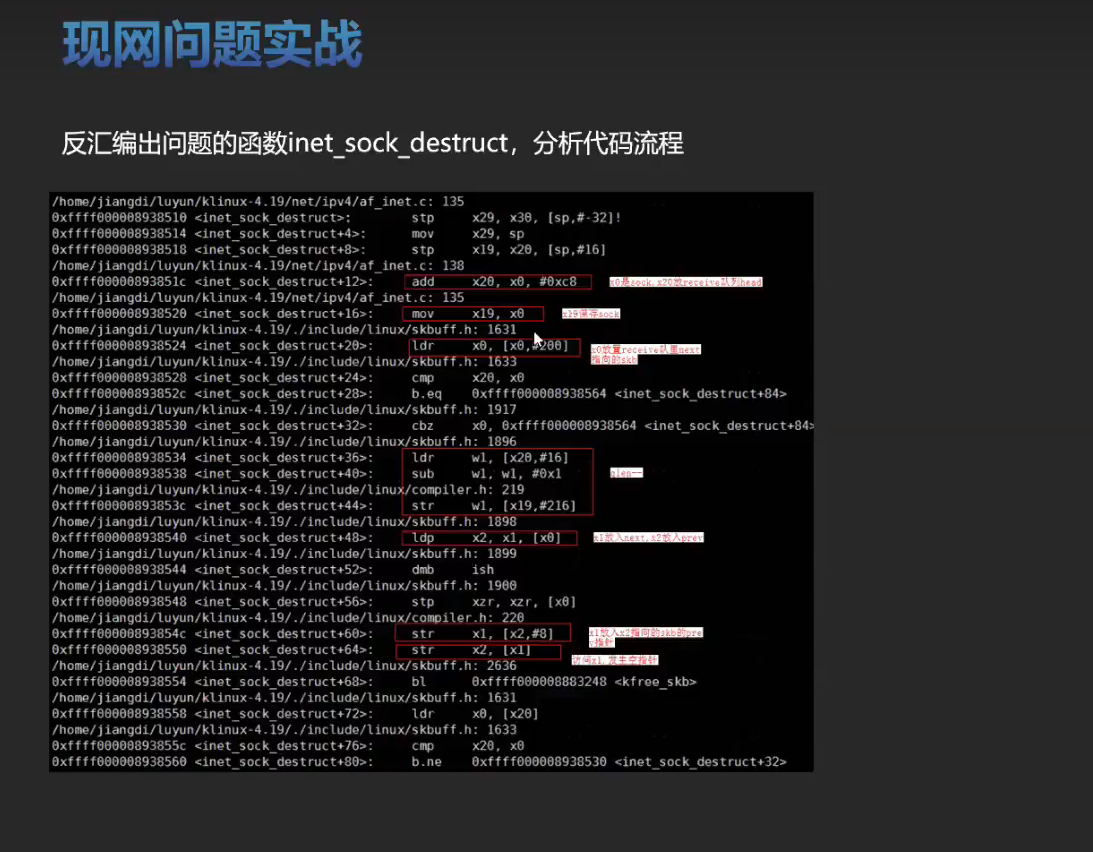
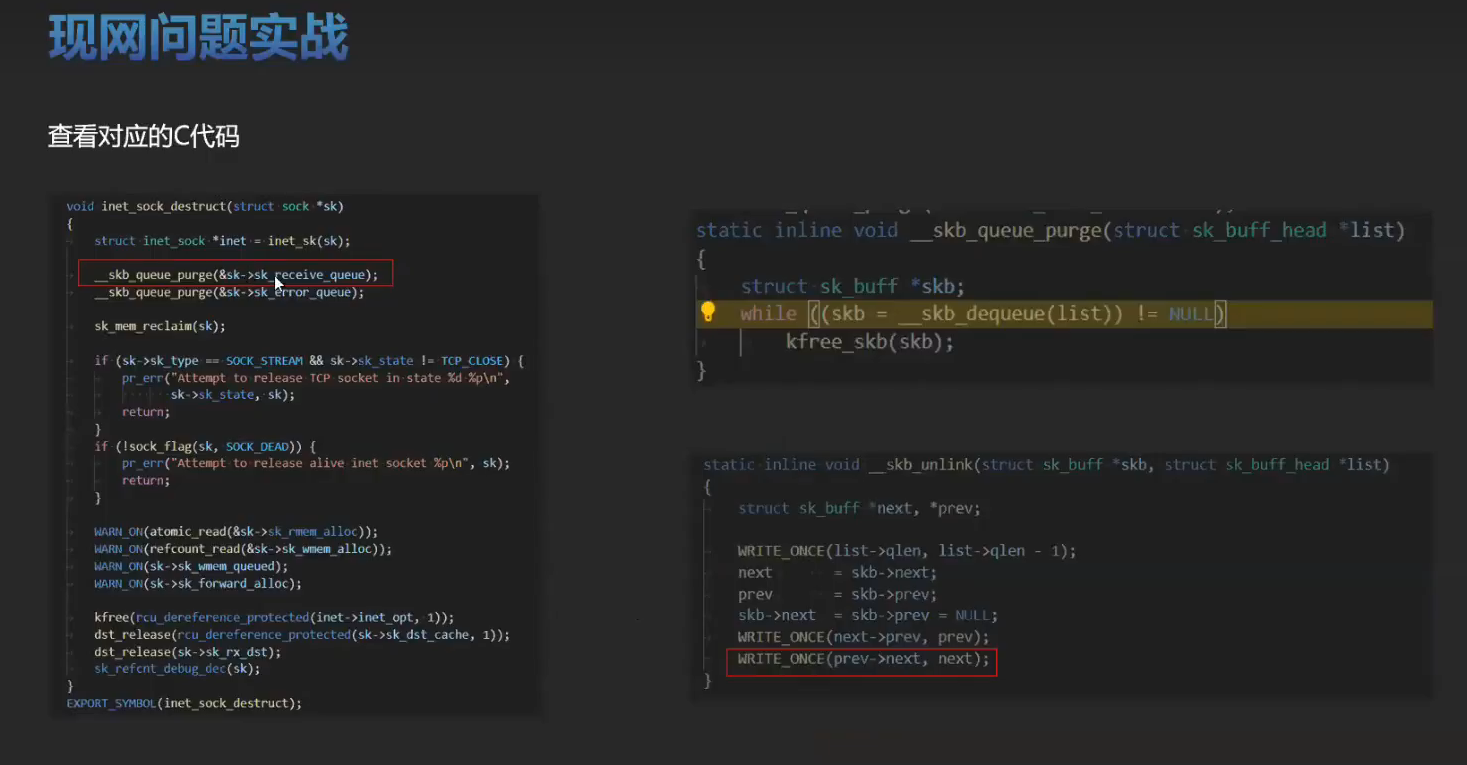
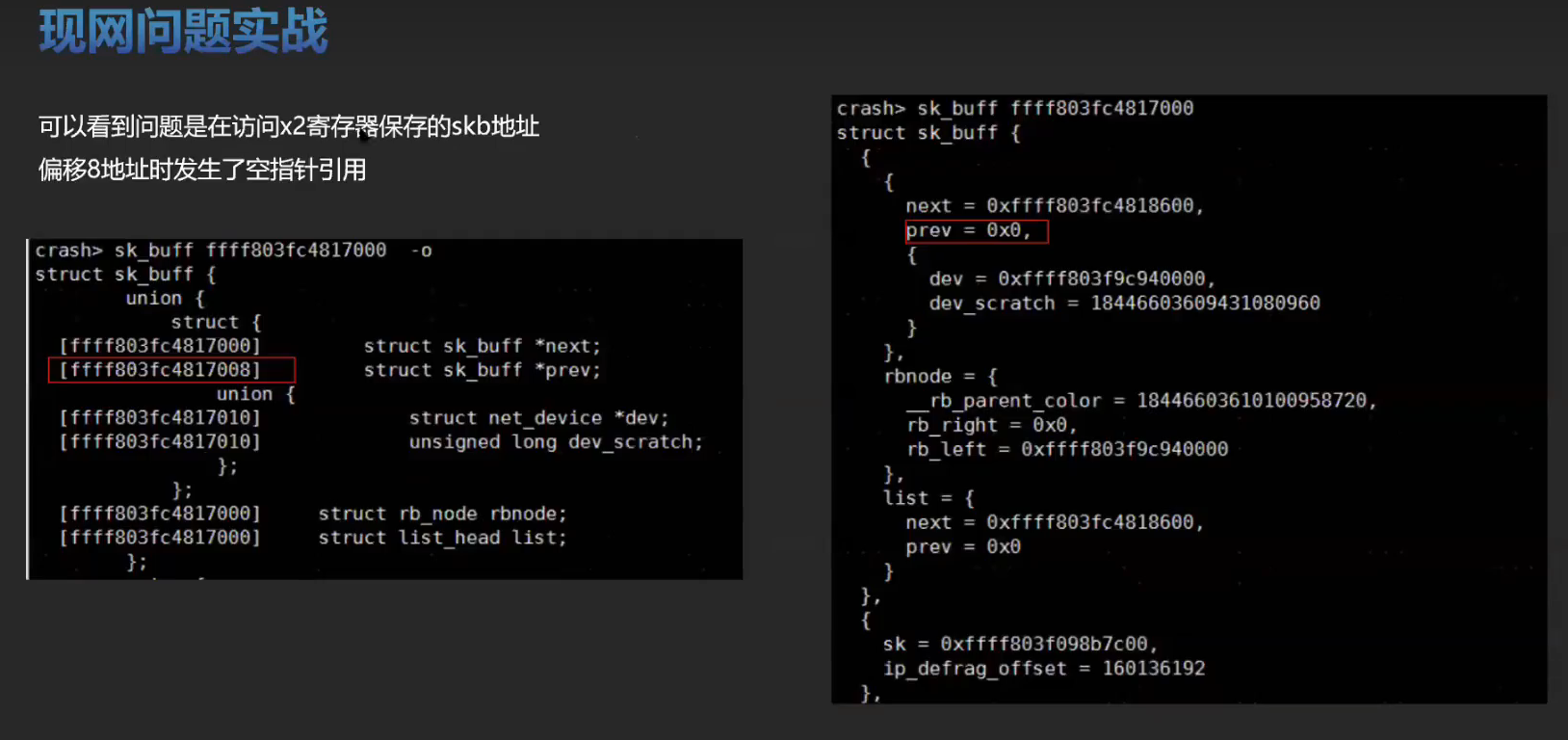
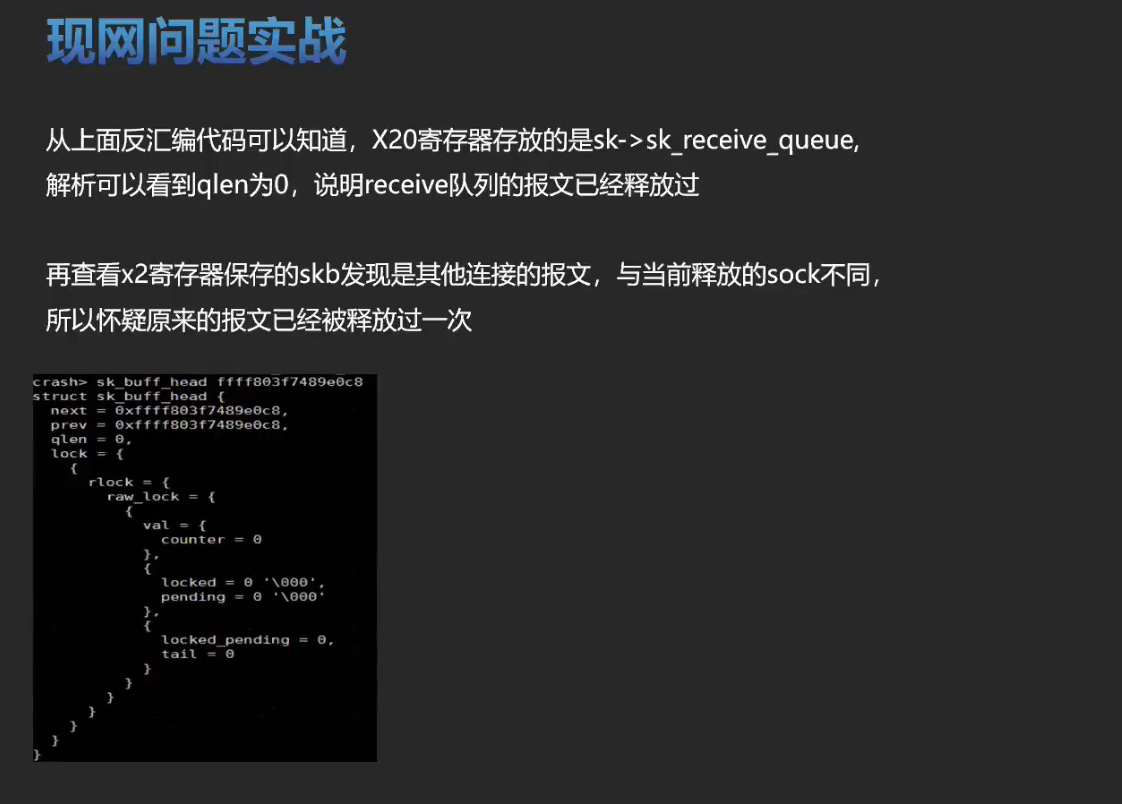

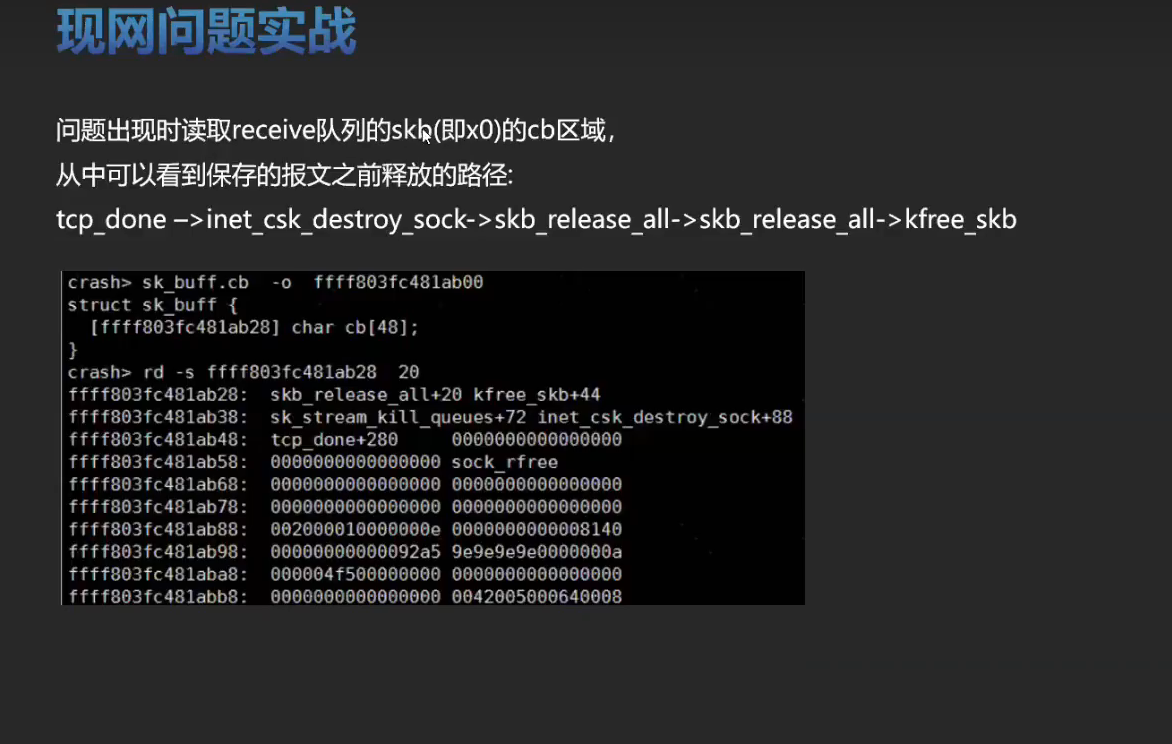
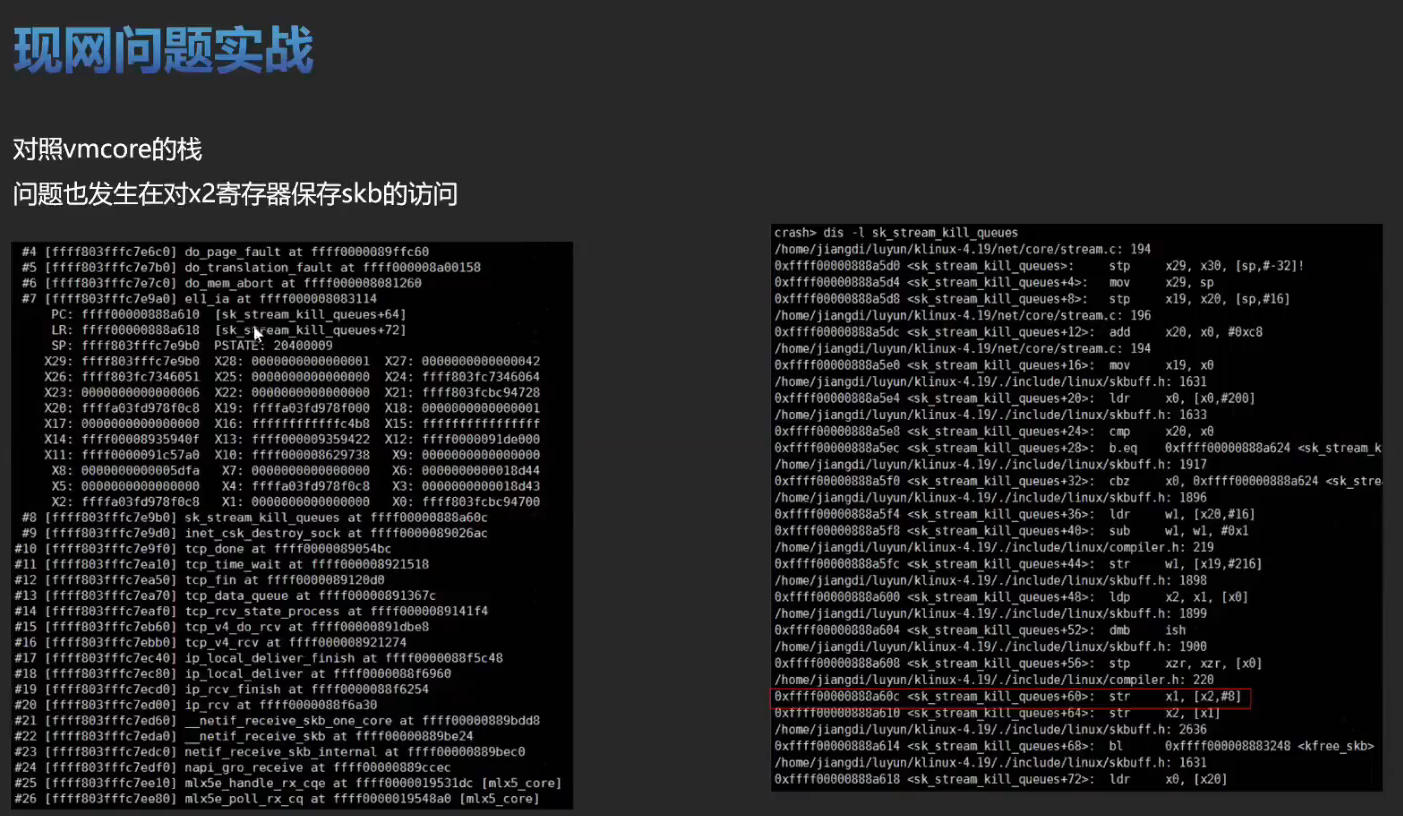
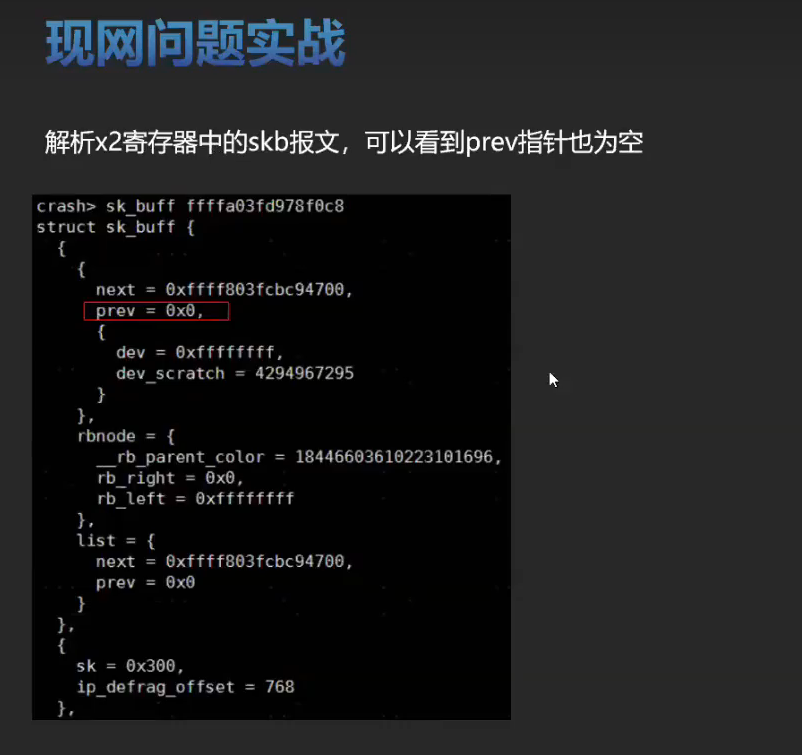



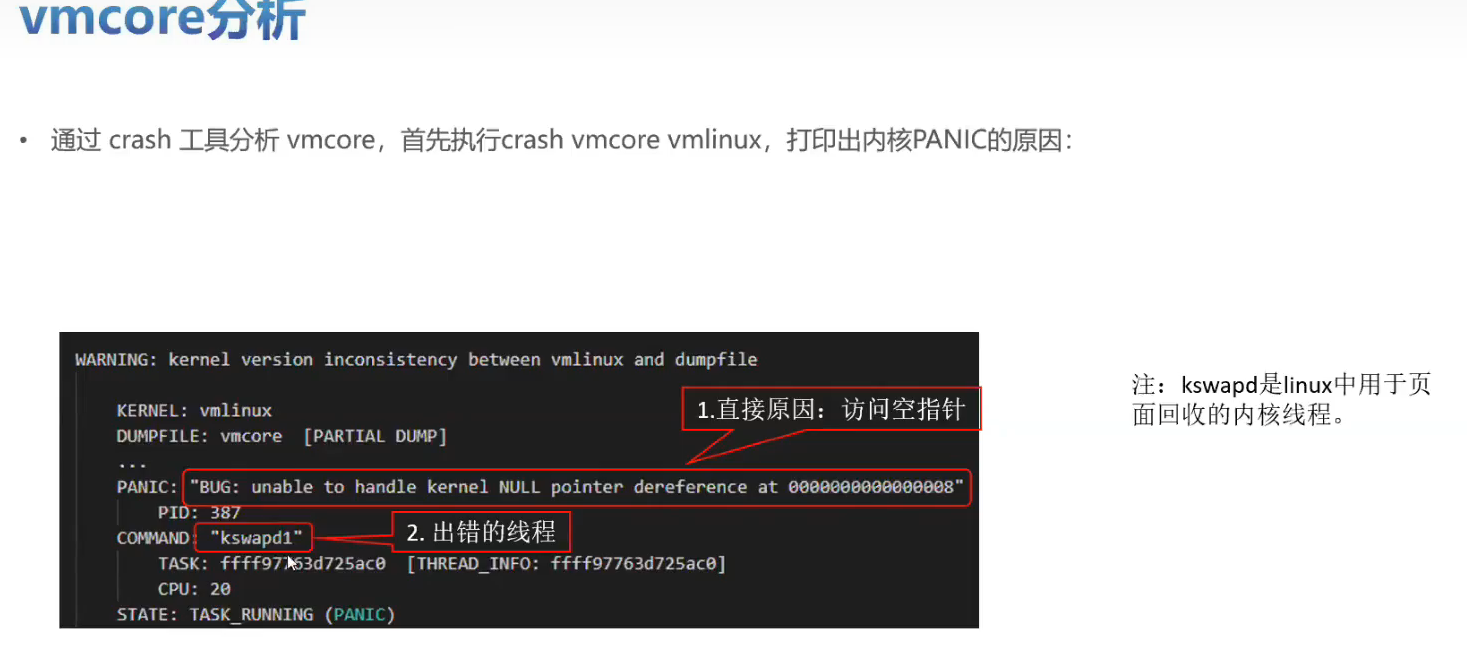
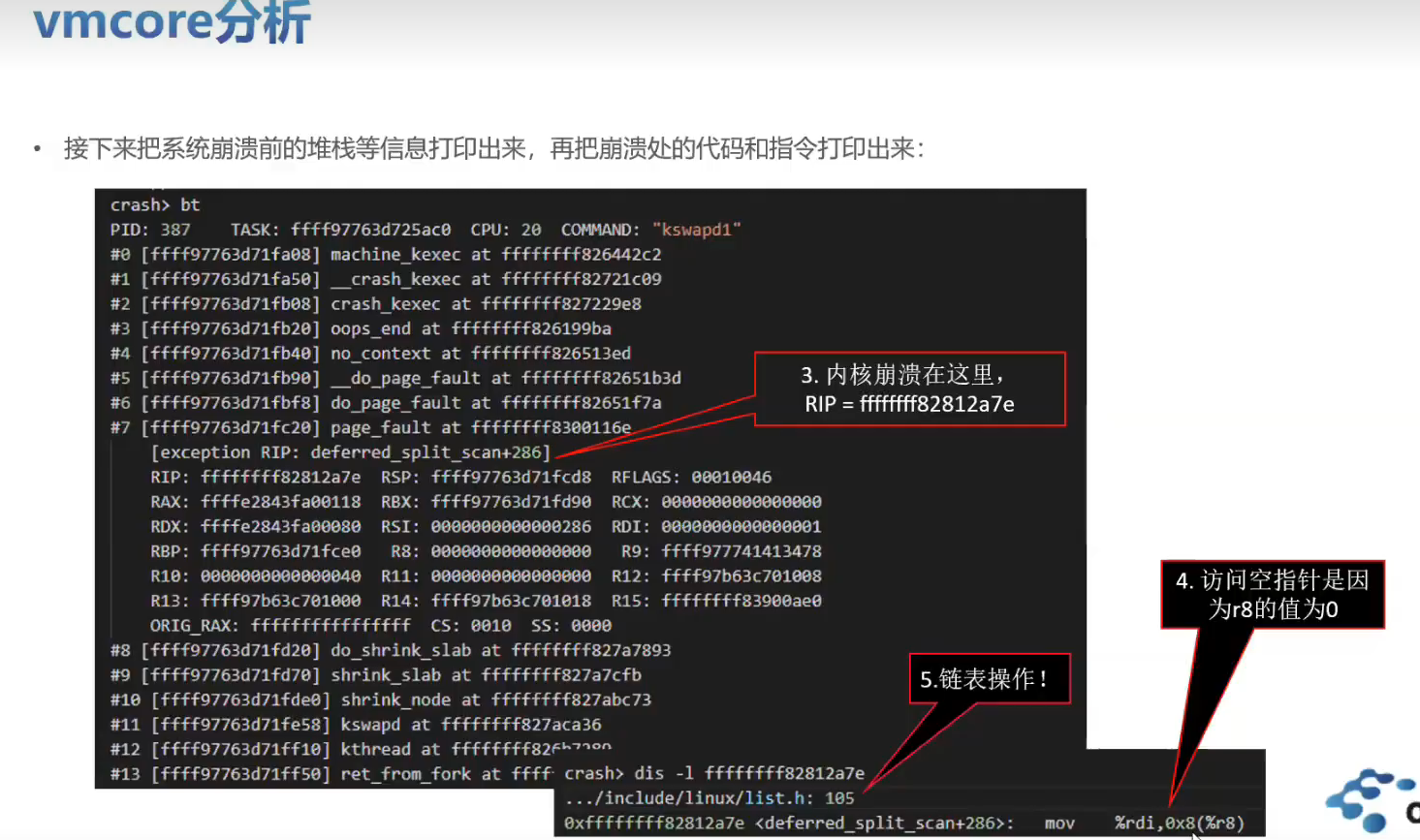
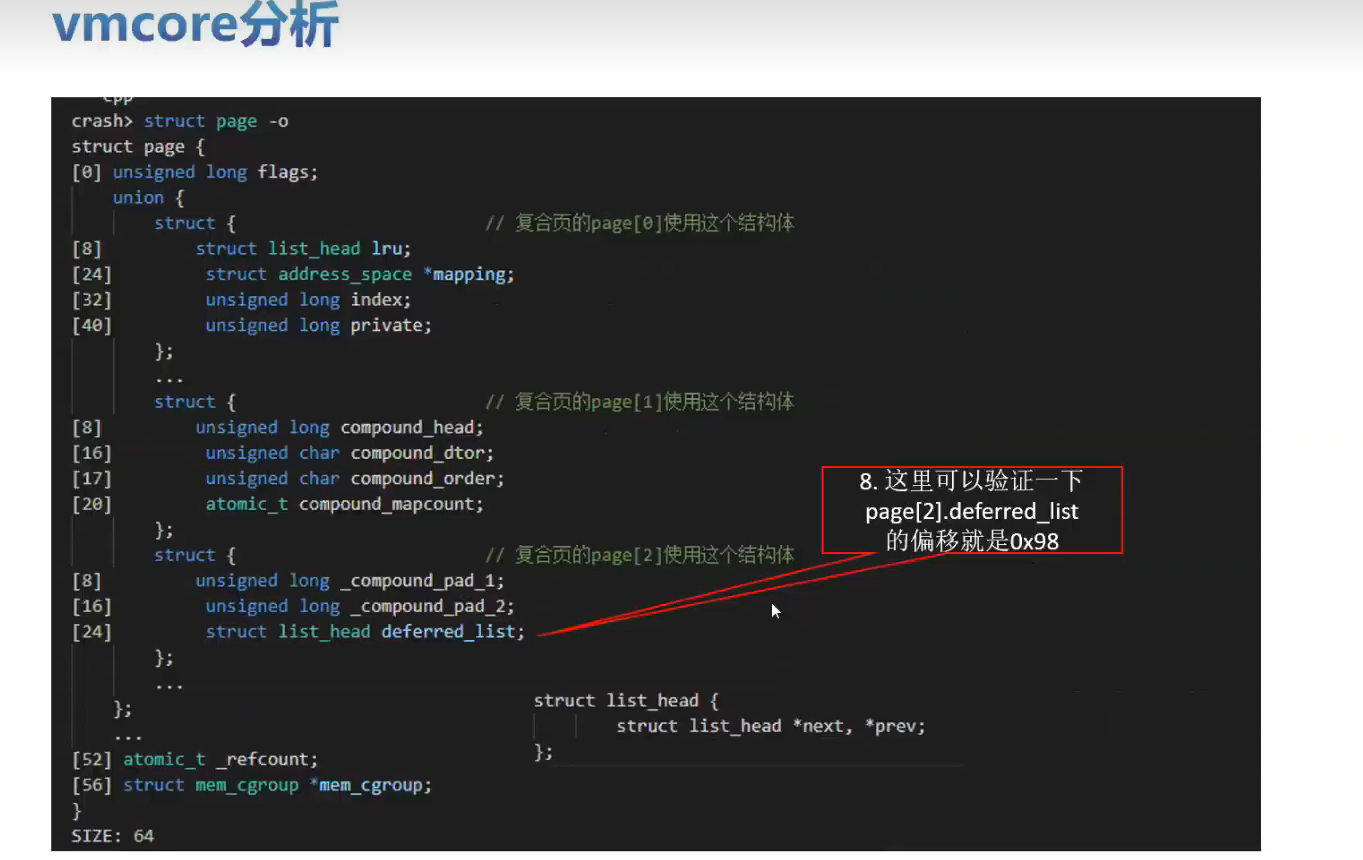
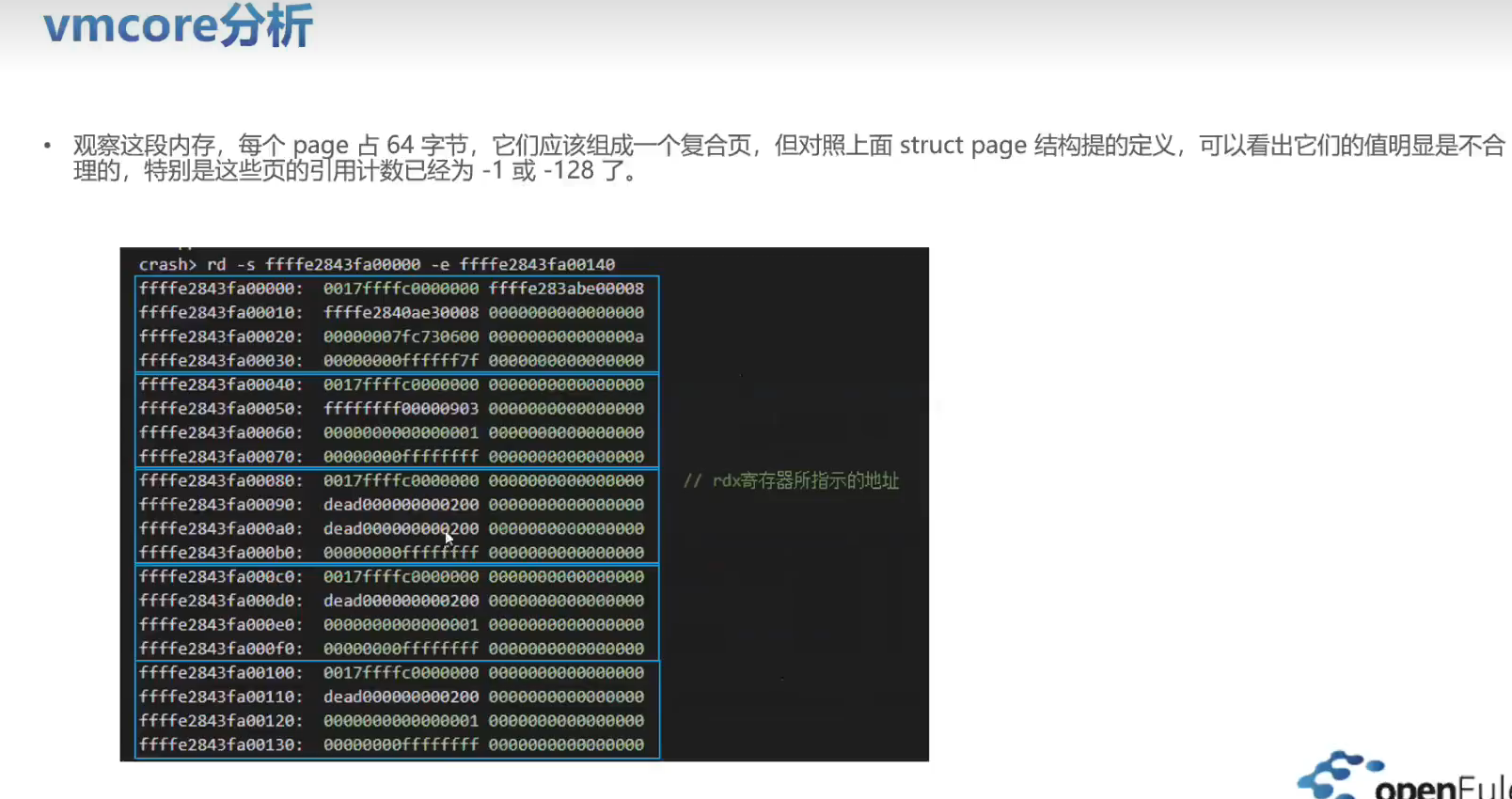
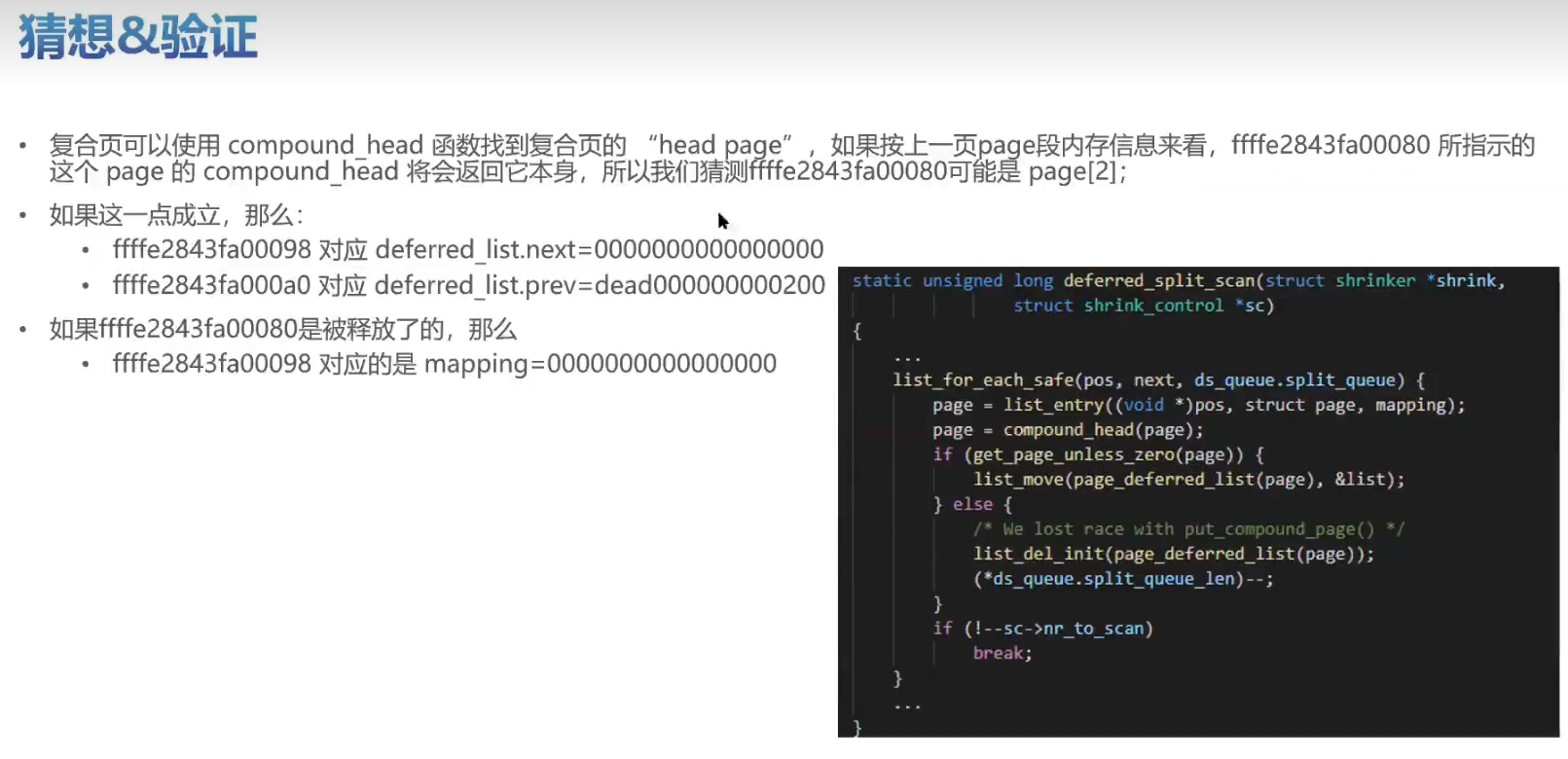

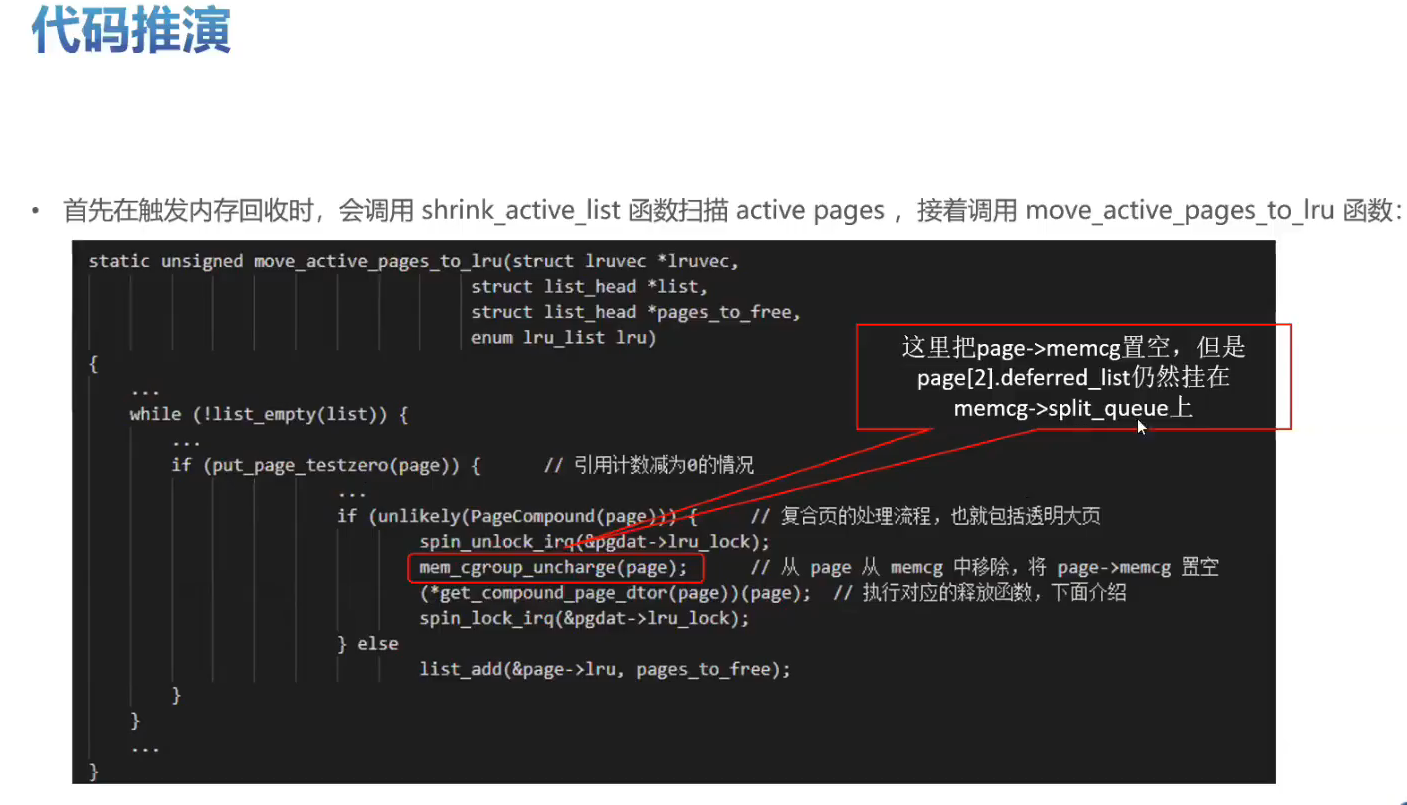
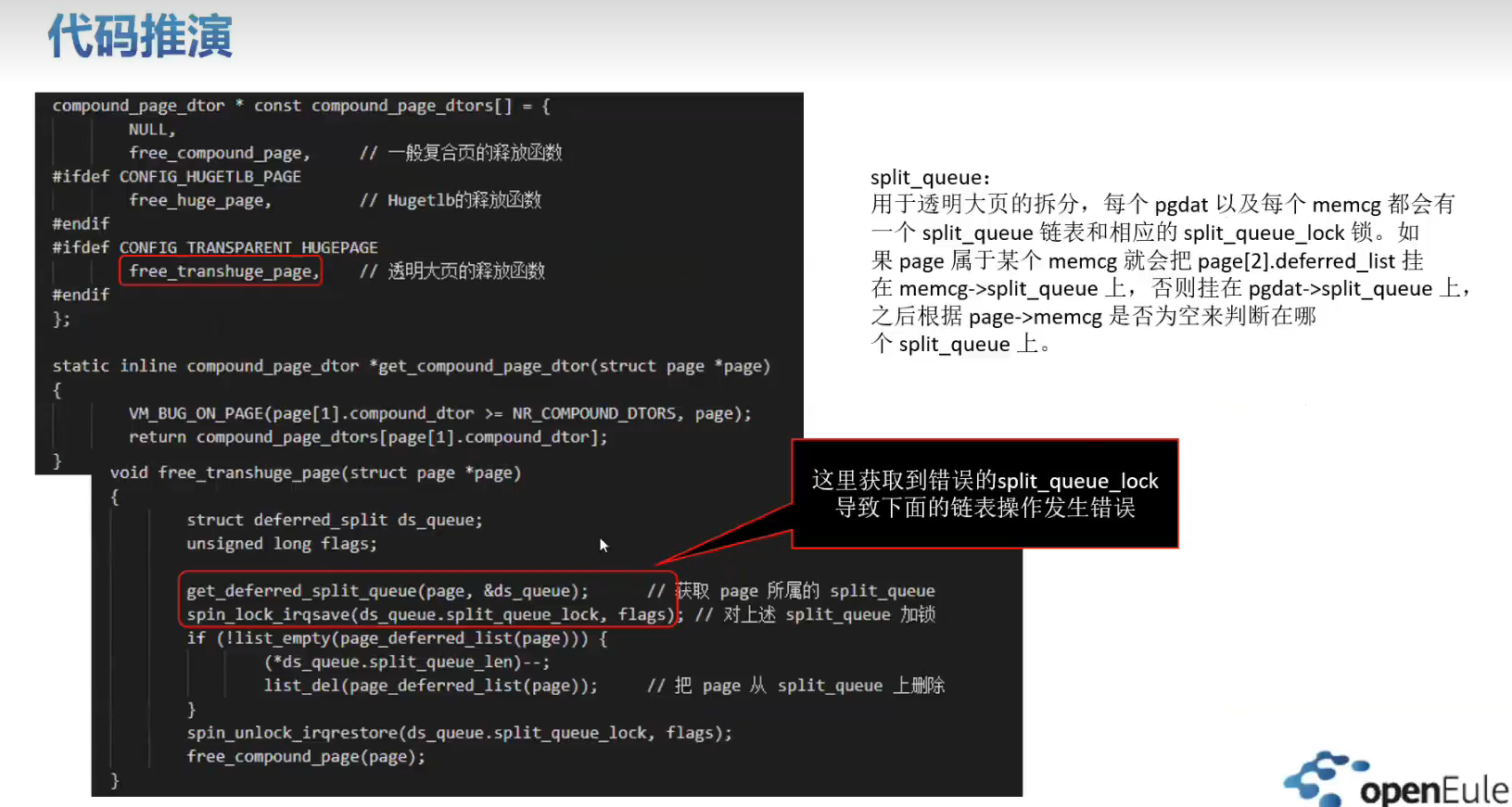
实战训练
有一个空指针的问题可以分析一下。将内核源码,vmcore ,vmlinux 这三个文件放在一起。比如: /root/linux-4.19.0-91.152.29 下。
crash vmlinux vmcore
sys
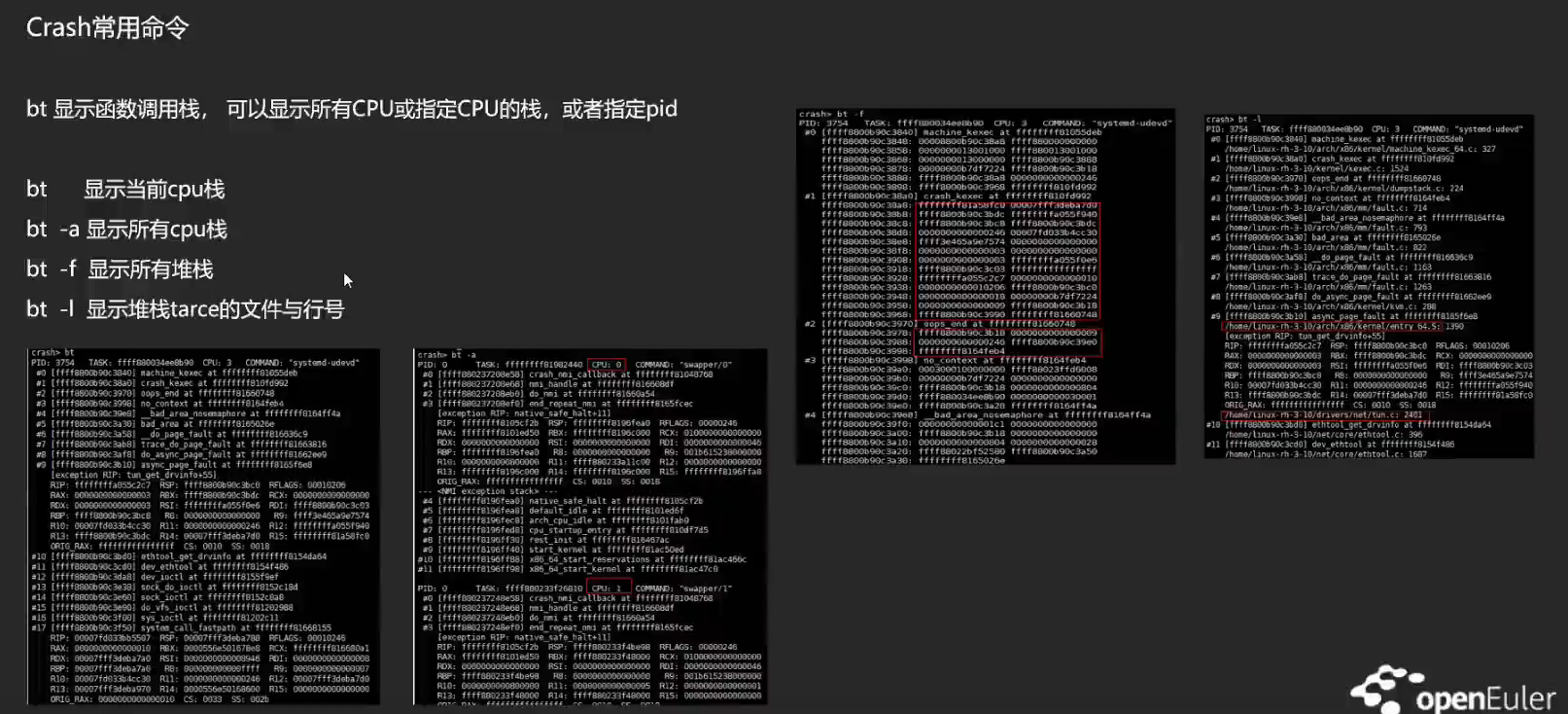
bt ,这个显示的是出问题的 CPU 上面的堆栈,用 bt -l 更常用一些。
log ,查看 dmesg 日志
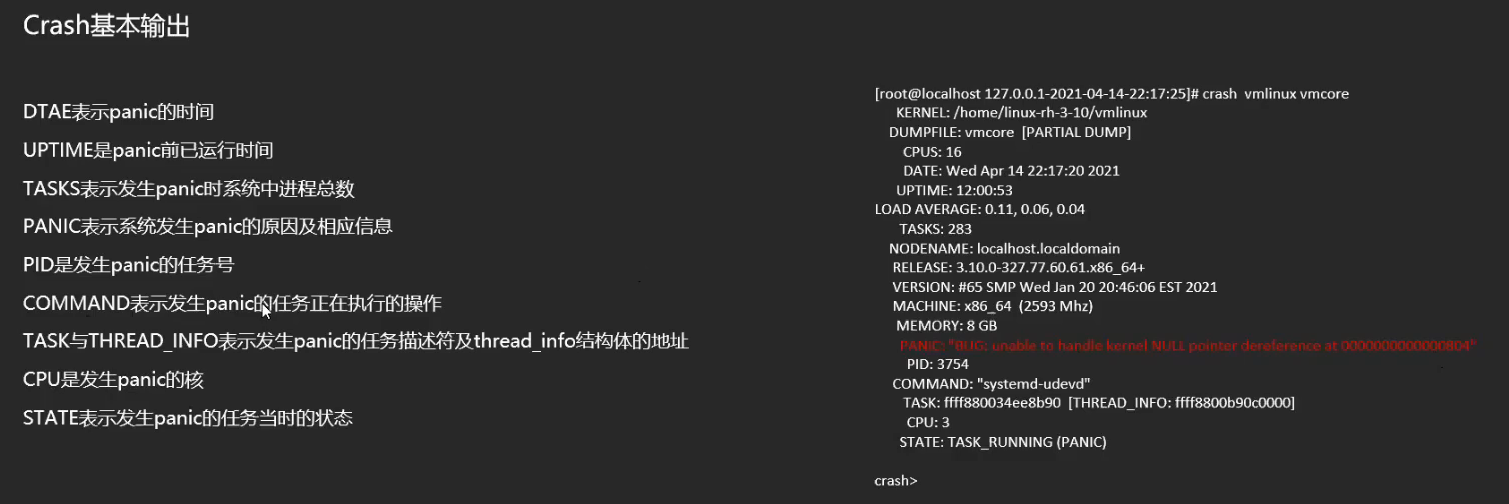
PID: 0 TASK: ffff9051fde18000 CPU: 119 COMMAND: "swapper/119"
#0 [ffff9051ffbc3b58] machine_kexec at ffffffffa685e85e
#1 [ffff9051ffbc3bb0] __crash_kexec at ffffffffa695f53d
#2 [ffff9051ffbc3c78] panic at ffffffffa7198494
#3 [ffff9051ffbc3cf8] oops_end.cold.9 at ffffffffa7192098
#4 [ffff9051ffbc3d18] no_context at ffffffffa686cb6c
#5 [ffff9051ffbc3d70] __do_page_fault at ffffffffa686d316
#6 [ffff9051ffbc3de0] do_page_fault at ffffffffa686d782
#7 [ffff9051ffbc3e10] page_fault at ffffffffa72011be
[exception RIP: unknown or invalid address]
RIP: 0000000000000000 RSP: ffff9051ffbc3ec0 RFLAGS: 00010206
RAX: 0000000000000000 RBX: 0000000000000100 RCX: 0000000000000040
RDX: ffff9051ffbc3ef0 RSI: 0000000000000000 RDI: ffff9050a78aa8e8
RBP: ffff9050a78aa8e8 R8: ffff9051ffbe0370 R9: ffff9051ffbe0328
R10: ffff9051ffbc3ef8 R11: 0000000000000000 R12: ffff9050a78aa8e8
R13: 0000000000000000 R14: ffff9051ffbc3ef0 R15: 0000000000000000
ORIG_RAX: ffffffffffffffff CS: 0010 SS: 0018
#8 [ffff9051ffbc3ec0] call_timer_fn at ffffffffa693d5bb
#9 [ffff9051ffbc3ee8] run_timer_softirq at ffffffffa693e047
#10 [ffff9051ffbc3f70] __softirqentry_text_start at ffffffffa74000cf
#11 [ffff9051ffbc3fc8] irq_exit at ffffffffa68bee71
#12 [ffff9051ffbc3fd8] smp_apic_timer_interrupt at ffffffffa7202714
#13 [ffff9051ffbc3ff0] apic_timer_interrupt at ffffffffa7201c6f
--- <IRQ stack> ---
#14 [ffffa7230cd23df8] apic_timer_interrupt at ffffffffa7201c6f
[exception RIP: native_safe_halt+14]
RIP: ffffffffa71d79ae RSP: ffffa7230cd23ea8 RFLAGS: 00000246
RAX: ffffffffa71d75e0 RBX: ffffffffa807b020 RCX: 0000000000000001
RDX: 000000001cf49a8e RSI: 0000000000000083 RDI: ffff9051ffbe93c0
RBP: 0000000000000077 R8: ffff9051ffbe3040 R9: ffff9061d8fee820
R10: 0000000000000000 R11: 0000000000000bc7 R12: 0000000000000000
R13: 0000000000000000 R14: 0000000000000000 R15: 0000000000000000
ORIG_RAX: ffffffffffffff13 CS: 0010 SS: 0018
#15 [ffffa7230cd23ea8] default_idle at ffffffffa71d75fc
#16 [ffffa7230cd23ed0] do_idle at ffffffffa68efbf3
#17 [ffffa7230cd23f10] cpu_startup_entry at ffffffffa68efe0f
#18 [ffffa7230cd23f30] start_secondary at ffffffffa68543ac
#19 [ffffa7230cd23f50] secondary_startup_64 at ffffffffa68000f7
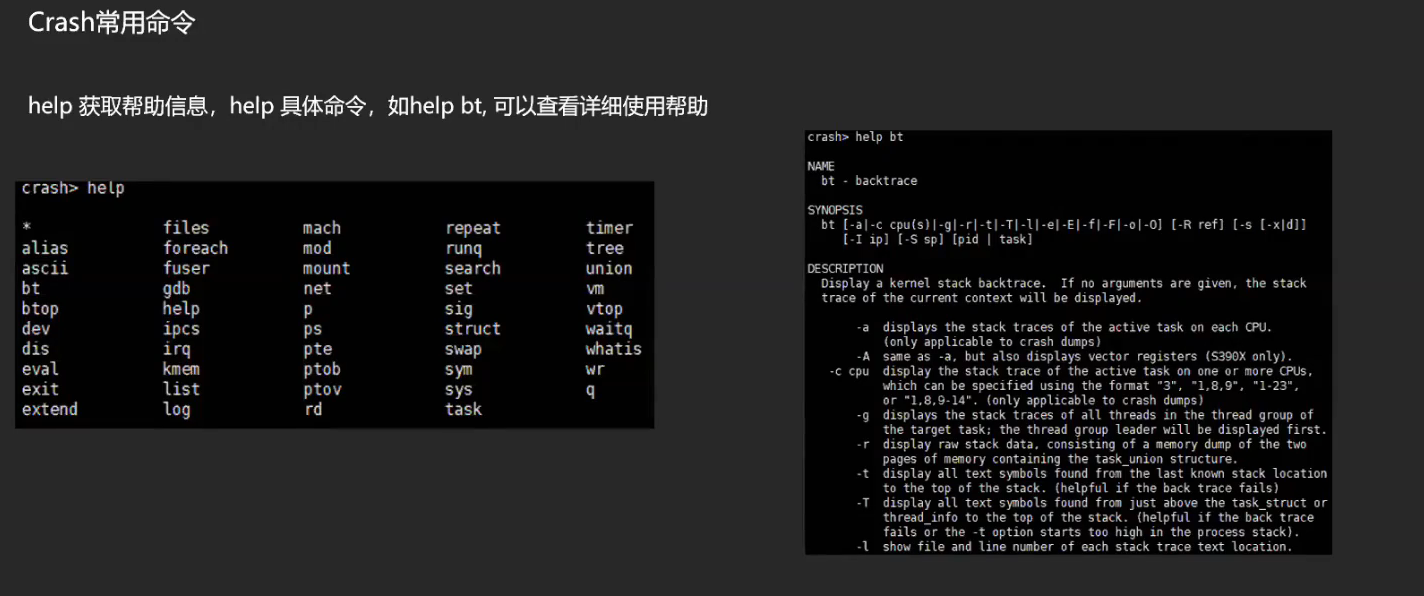
help bt 从这个里看到 -r 和 -l 两个选项是什么作用。
-r display raw stack data, consisting of a memory dump of the two pages of memory containing the task_union structure.
-l show file and line number of each stack trace text location.
rd 查看变量的内存值
dis -rl ,查看代码的位置。
看 crash 的崩溃,切记不能心急;因为分析 crash 是一个复杂的过程。过程中一定会遇到不懂的汇编,以及不懂的上下文代码。一定要搞的比较清楚了之后,才能理出来思路。否则 crash 不如不看。看了也会卡在一个比较容易分析到的位置而断开思路。
crash 的本质是理解一个汇编的流程,找到汇编出错的根本原因。再通过找到对应的 C 语言上下文来分析出错的根本原因是什么。之前一直比较弱的汇编现在必须要会了。
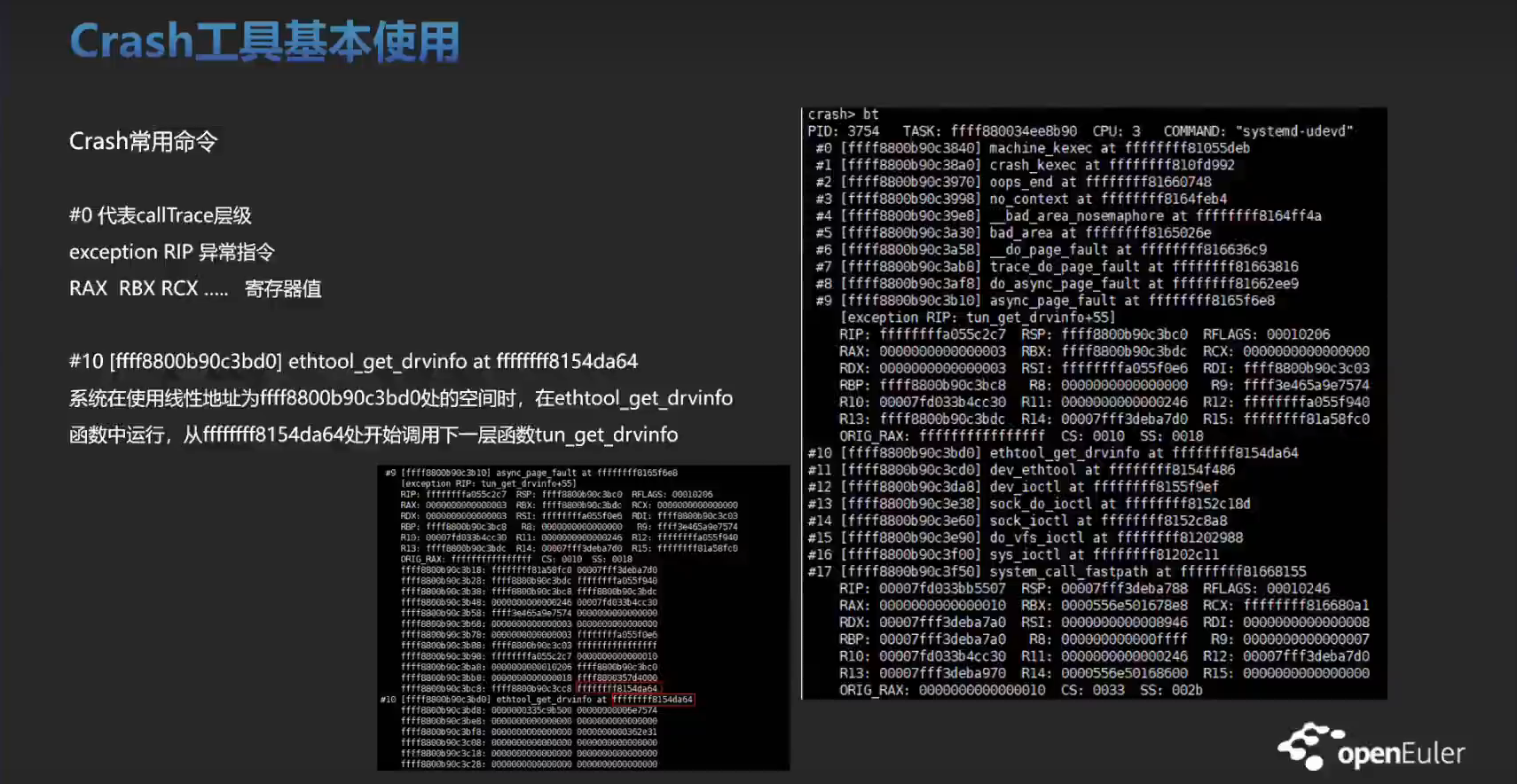
crash 的 bt 该如何看?
以堆栈中的第一个栈 #0 来举例:
#0 [ffff9051ffbc3b58] machine_kexec at ffffffffa685e85e
- #0
堆栈帧编号:#0 表示这是堆栈跟踪中的第 0 行,通常是崩溃发生的地方。它指向的是堆栈的最顶层(最新的调用栈),也就是说,这是当前栈帧的最开始位置。栈帧编号通常从 0 开始递增。
- [ffff9051ffbc3b58]
内存地址:这一部分表示一个内存地址 ffff9051ffbc3b58,它指向崩溃发生时的某个内存位置,通常是相关的函数调用栈或者数据结构。这个地址通常是某个栈变量、结构体或者函数的地址,也可能是堆栈上当前执行的指令所在的地址。需要注意的是,地址的格式通常为 64 位地址(0x 开头),但是在某些日志中,可能使用了短地址格式。
- machine_kexec
函数名称:machine_kexec 是内核中的一个函数名,通常用于处理 kexec 相关的操作。kexec 是一个在 Linux 中用来直接加载并启动一个新的内核的机制,它绕过了正常的引导过程。这说明崩溃发生时执行的代码正在调用或处于 machine_kexec 函数中,可能是因为内核崩溃后进行 kexec 重启操作。
- at ffffffffa685e85e
指令地址:at ffffffffa685e85e 表示函数 machine_kexec 中当前执行指令的内存地址。这个地址是内核代码在发生崩溃时正在执行的地方。地址 fffffffa685e85e 表示函数中的特定位置。这个地址通常是内核映像加载后的虚拟地址。如果你有内核符号表或调试符号,使用该地址可以帮助定位到具体的内核源代码行。
所以关键是看的 at 后面的指令地址,还有就是反推函数当中各个变量的值是什么。
crash 没有什么神秘的,也没有什么难的。就是把能找到的信息,能推理到的信息全部推理到。仅此而已。
上面为什么把中断的栈和内核其它的栈分开来显示呢?
这个也可以问 GPT ,它的回答是:
普通进程上下文:当内核执行普通进程时,堆栈是由进程的执行流维护的。进程执行时,CPU 状态(包括堆栈指针)会随着进程切换而改变,堆栈记录的是当前执行进程的调用历史。
IRQ上下文:中断处理程序是由硬件触发的,通常会在当前执行的进程上下文中暂停执行,转而执行中断处理程序。中断处理程序运行时使用的是不同的堆栈(通常是专门为中断处理设置的内核堆栈)。
crash 的变量解析方法:
https://blog.csdn.net/RJ436/article/details/128985165
交不会与学不会是两方面的能力的表现。研究问题最重要的是学习能力,而把问题讲明白,讲清楚则是另外一种表达能力。两方面的能力都很重要,但如果说最重的能力,那肯定是学习能力。因为一个人只要不是老师,那就没有 kabi 要把别人教会。恩,大概就是这个样子吧。
看不懂,学不会,可以先把疑问记下来。加上一段较长时间的思考,就能把问题逐渐想明白。
欧拉社区的讲解讲的还是比较系统和清晰的。
函数调用的过程首先要把返回值压栈。crash 的栈空间是连续的。自下向上不断增长地址。用 bt -F 就可以看到。
寄存器的计算
有一些常用的 crash 命令,比如:kmem -o 看一下所有 CPU 的段寄存器地址。再比如 x /10xg + 地址值 来看10 个16 进制 64 位的地址处的值。
crash 分析的问题有不少是踩内存和多核并发的问题,通过寄存器来回溯栈最直接的手段。但是首先要明白一些汇编的基础,比如 x86 当中的段寄存器。crash 又把关键拉回到了汇编这部分来了。
汇编很简单:要素只有指令集架构(ISA ),MMU ,寄存器(甚至你根本不用管每个寄存器通常用来做什么,只需要看C源码反汇编出来的汇编代码具体是什么就行了)。汇编的难点在于调试,而单看每一个 ISA 指令都是明确且简单的。
总的来说:
汇编语言复杂度较高,主要是因为它的底层性质、需要直接控制硬件和内存、并且每一条指令都要手动编写,开发周期长,错误难以排查。
C语言相对复杂度较低,能够提供更高的抽象和可读性,更易于开发和维护,支持跨平台开发,并且有更强的工具和库支持。
我尝试问了一下 GPT 下面的问题:
段寄存器有什么用处?
arm当中有段寄存器吗?
你能把x86 和arm的汇编设计讲一下吗?好像也没有多少的寄存器。
x86 的mmu和arm的mmu有什么区别?
汇编复杂还是C语言程序复杂?
这些问题的答案太长了,我就不帖出来了。这次对 crash 的梳理就先到这里,以后用的多了,有心德之后我会再补充一下这块的知识。